Fuzzing is an effective technique for finding software vulnerabilities. Over the past few years Android has been focused on improving the effectiveness, scope, and convenience of fuzzing across the organization. This effort has directly resulted in improved test coverage, fewer security/stability bugs, and higher code quality. Our implementation of continuous fuzzing allows software teams to find new bugs/vulnerabilities, and prevent regressions automatically without having to manually initiate fuzzing runs themselves. This post recounts a brief history of fuzzing on Android, shares how Google performs fuzzing at scale, and documents our experience, challenges, and success in building an infrastructure for automating fuzzing across Android. If you’re interested in contributing to fuzzing on Android, we’ve included instructions on how to get started, and information on how Android’s VRP rewards fuzzing contributions that find vulnerabilities.
Fuzzing has been around for many years, and Android was among the early large software projects to automate fuzzing and prioritize it similarly to unit testing as part of the broader goal to make Android the most secure and stable operating system. In 2019 Android kicked off the fuzzing project, with the goal to help institutionalize fuzzing by making it seamless and part of code submission. The Android fuzzing project resulted in an infrastructure consisting of Pixel phones and Google cloud based virtual devices that enabled scalable fuzzing capabilities across the entire Android ecosystem. This project has since grown to become the official internal fuzzing infrastructure for Android and performs thousands of fuzzing hours per day across hundreds of fuzzers.
Step 1: Define and find all the fuzzers in Android repo
The first step is to integrate fuzzing into the Android build system (Soong) to enable build fuzzer binaries. While developers are busy adding features to their codebase, they can include a fuzzer to fuzz their code and submit the fuzzer alongside the code they have developed. Android Fuzzing uses a build rule called cc_fuzz (see example below). cc_fuzz (we also support rust_fuzz and java_fuzz) defines a Soong module with source file(s) and dependencies that can be built into a binary.
cc_fuzz { name: "fuzzer_foo", srcs: [ "fuzzer_foo.cpp", ], static_libs: [ "libfoo", ], host_supported: true, }
A packaging rule in Soong finds all of these cc_fuzz definitions and builds them automatically. The actual fuzzer structure itself is very simple and consists of one main method (LLVMTestOneInput):
#include <stddef.h> #include <stdint.h> extern "C" int LLVMFuzzerTestOneInput( const uint8_t *data, size_t size) { // Here you invoke the code to be fuzzed. return 0; }
This fuzzer gets automatically built into a binary and along with its static/dynamic dependencies (as specified in the Android build file) are packaged into a zip file which gets added to the main zip containing all fuzzers as shown in the example below.
Step 2: Ingest all fuzzers into Android builds
Once the fuzzers are found in the Android repository and they are built into binaries, the next step is to upload them to the cloud storage in preparation to run them on our backend. This process is run multiple times daily. The Android fuzzing infrastructure uses an open source continuous fuzzing framework (Clusterfuzz) to run fuzzers continuously on Android devices and emulators. In order to run the fuzzers on clusterfuzz, the fuzzers zip files are renamed after the build and the latest build gets to run (see diagram below):
The fuzzer zip file contains the fuzzer binary, corresponding dictionary as well as a subfolder containing its dependencies and the git revision numbers (sourcemap) corresponding to the build. Sourcemaps are used to enhance stack traces and produce crash reports.
Step 3: Run fuzzers continuously and find bugs
Running fuzzers continuously is done through scheduled jobs where each job is associated with a set of physical devices or emulators. A job is also backed by a queue that represents the fuzzing tasks that need to be run. These tasks are a combination of running a fuzzer, reproducing a crash found in an earlier fuzzing run, or minimizing the corpus, among other tasks.
Each fuzzer is run for multiple hours, or until they find a crash. After the run, Android fuzzing takes all of the interesting input discovered during the run and adds it to the fuzzer corpus. This corpus is then shared across fuzzer runs and grows over time. The fuzzer is then prioritized in subsequent runs according to the growth of new coverage and crashes found (if any). This ensures we provide the most effective fuzzers more time to run and find interesting crashes.
Step 4: Generate fuzzers line coverage
What good is a fuzzer if it’s not fuzzing the code you care about? To improve the quality of the fuzzer and to monitor the overall progress of Android fuzzing, two types of coverage metrics are calculated and available to Android developers. The first metric is for edge coverage which refers to edges in the Control Flow Graph (CFG). By instrumenting the fuzzer and the code being fuzzed, the fuzzing engine can track small snippets of code that get triggered every time execution flow reaches them. That way, fuzzing engines know exactly how many (and how many times) each of these instrumentation points got hit on every run so they can aggregate them and calculate the coverage.
INFO: Seed: 2859304549 INFO: Loaded 1 modules (773 inline 8-bit counters): 773 [0x5610921000, 0x5610921305), INFO: Loaded 1 PC tables (773 PCs): 773 [0x5610921308,0x5610924358), INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes INFO: A corpus is not provided, starting from an empty corpus #2 INITED cov: 2 ft: 2 corp: 1/1b lim: 4 exec/s: 0 rss: 24Mb #413 NEW cov: 3 ft: 3 corp: 2/9b lim: 8 exec/s: 0 rss: 24Mb L: 8/8 MS: 1 InsertRepeatedBytes- #3829 NEW cov: 4 ft: 4 corp: 3/17b lim: 38 exec/s: 0 rss: 24Mb L: 8/8 MS: 1 ChangeBinInt- ...
Line coverage inserts instrumentation points specifying lines in the source code. Line coverage is very useful for developers as they can pinpoint areas in the code that are not covered and update their fuzzers accordingly to hit those areas in future fuzzing runs.
Drilling into any of the folders can show the stats per file:
Further clicking on one of the files shows the lines that were touched and lines that never got coverage. In the example below, the first line has been fuzzed ~5 million times, but the fuzzer never makes it into lines 3 and 4, indicating a gap in the coverage for this fuzzer.
We have dashboards internally that measure our fuzzing coverage across our entire codebase. In order to generate these coverage dashboards yourself, you follow these steps.
Another measurement of the quality of the fuzzers is how many fuzzing iterations can be done in one second. It has a direct relationship with the computation power and the complexity of the fuzz target. However, this parameter alone can not measure how good or effective the fuzzing is.
Android fuzzing utilizes the Clusterfuzz fuzzing infrastructure to handle any found crashes and file a ticket to the Android security team. Android security makes an assessment of the crash based on the Android Severity Guidelines and then routes the vulnerability to the proper team for remediation. This entire process of finding the reproducible crash, routing to Android Security, and then assigning the issue to a team responsible can take as little as two hours, and up to a week depending on the type of crash and the severity of the vulnerability.
One example of a recent fuzzer success is (CVE 2022-20473), where an internal team wrote a 20-line fuzzer and submitted it to run on Android fuzzing infra. Within a day, the fuzzer was ingested and pushed to our fuzzing infrastructure to begin fuzzing, and shortly found a critical severity vulnerability! A patch for this CVE has been applied by the service team.
The Android Open Source Project (AOSP) is a large and complex project with many contributors. As a result, there are thousands of changes made to the project every day. These changes can be anything from small bug fixes to large feature additions, and fuzzing helps to find vulnerabilities that may be inadvertently introduced and not caught during code review.
Continuous fuzzing has helped to find these vulnerabilities before they are introduced in production and exploited by attackers. One real-life example is (CVE-2023-21041), a vulnerability discovered by a fuzzer written three years ago. This vulnerability affected Android firmware and could have led to local escalation of privilege with no additional execution privileges needed. This fuzzer was running for many years with limited findings until a code regression led to the introduction of this vulnerability. This CVE has since been patched.
Android has been a huge proponent of Rust, with Android 13 being the first Android release with the majority of new code in a memory safe language. The amount of new memory-unsafe code entering Android has decreased, but there are still millions of lines of code that remain, hence the need for fuzzing persists.
Our work does not stop with non-memory unsafe languages, and we encourage fuzzer development in languages like Rust as well. While fuzzing won’t find common vulnerabilities that you would expect to see memory unsafe languages like C/C++, there have been numerous non-security issues discovered and remediated which contribute to the overall stability of Android.
In addition to generic C/C++ binaries issues such as missing dependencies, fuzzers can have their own classes of problems:
Low executions per second: in order to fuzz efficiently, the number of mutations has to be in the order of hundreds per second otherwise the fuzzing will take a very long time to cover the code. We addressed this issue by adding a set of alerts that continuously monitor the health of the fuzzers as well as any sudden drop in coverage. Once a fuzzer is identified as underperforming, an automated email is sent to the fuzzer author with details to help them improve the fuzzer.
Fuzzing the wrong code: Like all resources, fuzzing resources are limited. We want to ensure that those resources give us the highest return, and that generally means devoting them towards fuzzing code that processes untrusted (i.e. potentially attacker controlled) inputs. This can cover any way that the phone can receive input including Bluetooth, NFC, USB, web, etc. Parsing structured input is particularly interesting since there is room for programming errors due to specs complexity. Code that generates output is not particularly interesting to fuzz. Similarly internal code that is not exposed publicly is also less of a security concern. We addressed this issue by identifying the most vulnerable code (see the following section).
In order to fuzz the most important components of the Android source code, we focus on libraries that have:
We’re constantly writing and improving fuzzers internally to cover some of the most sensitive areas of Android, but there is always room for improvement. If you’d like to get started writing your own fuzzer for an area of AOSP, you’re welcome to do so to make Android more secure (example CL):
Get started by reading our documentation on Fuzzing with libFuzzer and check your fuzzer into the Android Open Source project. If your fuzzer finds a bug, you can submit it to the Android Bug Bounty Program and could be eligible for a reward!
Since 2016, OSS-Fuzz has been at the forefront of automated vulnerability discovery for open source projects. Vulnerability discovery is an important part of keeping software supply chains secure, so our team is constantly working to improve OSS-Fuzz. For the last few months, we’ve tested whether we could boost OSS-Fuzz’s performance using Google’s Large Language Models (LLM).
This blog post shares our experience of successfully applying the generative power of LLMs to improve the automated vulnerability detection technique known as fuzz testing (“fuzzing”). By using LLMs, we’re able to increase the code coverage for critical projects using our OSS-Fuzz service without manually writing additional code. Using LLMs is a promising new way to scale security improvements across the over 1,000 projects currently fuzzed by OSS-Fuzz and to remove barriers to future projects adopting fuzzing.
We created the OSS-Fuzz service to help open source developers find bugs in their code at scale—especially bugs that indicate security vulnerabilities. After more than six years of running OSS-Fuzz, we now support over 1,000 open source projects with continuous fuzzing, free of charge. As the Heartbleed vulnerability showed us, bugs that could be easily found with automated fuzzing can have devastating effects. For most open source developers, setting up their own fuzzing solution could cost time and resources. With OSS-Fuzz, developers are able to integrate their project for free, automated bug discovery at scale.
Since 2016, we’ve found and verified a fix for over 10,000 security vulnerabilities. We also believe that OSS-Fuzz could likely find even more bugs with increased code coverage. The fuzzing service covers only around 30% of an open source project’s code on average, meaning that a large portion of our users’ code remains untouched by fuzzing. Recent research suggests that the most effective way to increase this is by adding additional fuzz targets for every project—one of the few parts of the fuzzing workflow that isn’t yet automated.
When an open source project onboards to OSS-Fuzz, maintainers make an initial time investment to integrate their projects into the infrastructure and then add fuzz targets. The fuzz targets are functions that use randomized input to test the targeted code. Writing fuzz targets is a project-specific and manual process that is similar to writing unit tests. The ongoing security benefits from fuzzing make this initial investment of time worth it for maintainers, but writing a comprehensive set of fuzz targets is a tough expectation for project maintainers, who are often volunteers.
But what if LLMs could write additional fuzz targets for maintainers?
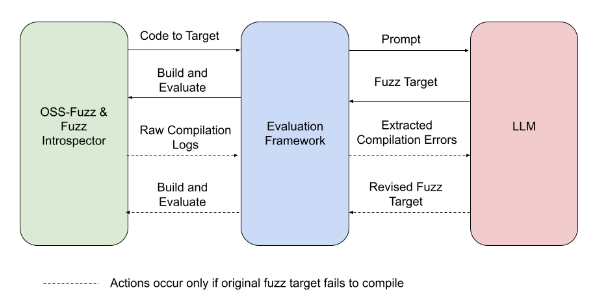
To discover whether an LLM could successfully write new fuzz targets, we built an evaluation framework that connects OSS-Fuzz to the LLM, conducts the experiment, and evaluates the results. The steps look like this:
Experiment overview: The experiment pictured above is a fully automated process, from identifying target code to evaluating the change in code coverage.
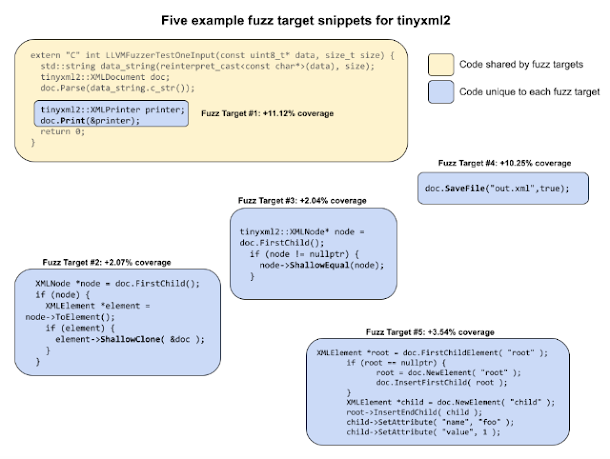
At first, the code generated from our prompts wouldn’t compile; however, after several rounds of prompt engineering and trying out the new fuzz targets, we saw projects gain between 1.5% and 31% code coverage. One of our sample projects, tinyxml2, went from 38% line coverage to 69% without any interventions from our team. The case of tinyxml2 taught us: when LLM-generated fuzz targets are added, tinyxml2 has the majority of its code covered.
Example fuzz targets for tinyxml2: Each of the five fuzz targets shown is associated with a different part of the code and adds to the overall coverage improvement.
To replicate tinyxml2’s results manually would have required at least a day’s worth of work—which would mean several years of work to manually cover all OSS-Fuzz projects. Given tinyxml2’s promising results, we want to implement them in production and to extend similar, automatic coverage to other OSS-Fuzz projects.
Additionally, in the OpenSSL project, our LLM was able to automatically generate a working target that rediscovered CVE-2022-3602, which was in an area of code that previously did not have fuzzing coverage. Though this is not a new vulnerability, it suggests that as code coverage increases, we will find more vulnerabilities that are currently missed by fuzzing.
Learn more about our results through our example prompts and outputs or through our experiment report.
In the next few months, we’ll open source our evaluation framework to allow researchers to test their own automatic fuzz target generation. We’ll continue to optimize our use of LLMs for fuzzing target generation through more model finetuning, prompt engineering, and improvements to our infrastructure. We’re also collaborating closely with the Assured OSS team on this research in order to secure even more open source software used by Google Cloud customers.
Our longer term goals include:
Adding LLM fuzz target generation as a fully integrated feature in OSS-Fuzz, with continuous generation of new targets for OSS-fuzz projects and zero manual involvement.
Extending support from C/C++ projects to additional language ecosystems, like Python and Java.
Automating the process of onboarding a project into OSS-Fuzz to eliminate any need to write even initial fuzz targets.
We’re working towards a future of personalized vulnerability detection with little manual effort from developers. With the addition of LLM generated fuzz targets, OSS-Fuzz can help improve open source security for everyone.
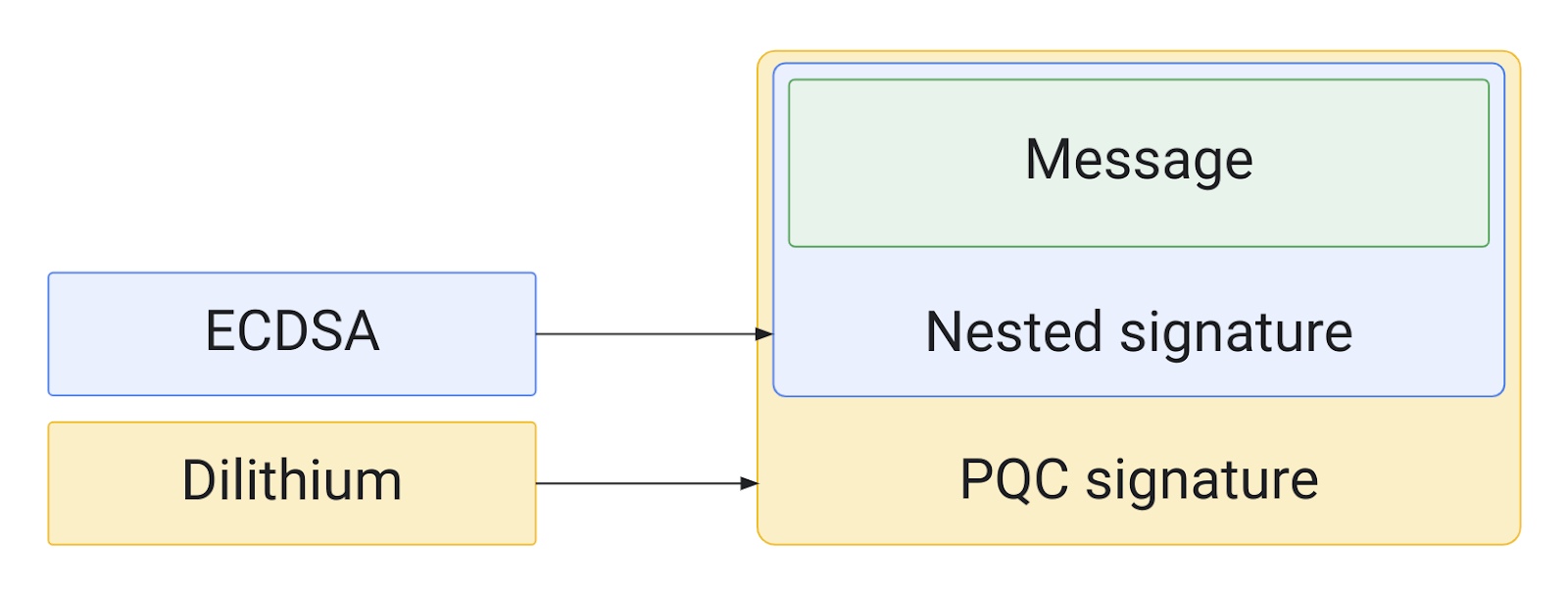
As part of our effort to deploy quantum resistant cryptography, we are happy to announce the release of the first quantum resilient FIDO2 security key implementation as part of OpenSK, our open source security key firmware. This open-source hardware optimized implementation uses a novel ECC/Dilithium hybrid signature schema that benefits from the security of ECC against standard attacks and Dilithium’s resilience against quantum attacks. This schema was co-developed in partnership with the ETH Zürich and won the ACNS secure cryptographic implementation workshop best paper.
Quantum processor
As progress toward practical quantum computers is accelerating, preparing for their advent is becoming a more pressing issue as time passes. In particular, standard public key cryptography which was designed to protect against traditional computers, will not be able to withstand quantum attacks. Fortunately, with the recent standardization of public key quantum resilient cryptography including the Dilithium algorithm, we now have a clear path to secure security keys against quantum attacks.
While quantum attacks are still in the distant future, deploying cryptography at Internet scale is a massive undertaking which is why doing it as early as possible is vital. In particular, for security keys this process is expected to be gradual as users will have to acquire new ones once FIDO has standardized post quantum cryptography resilient cryptography and this new standard is supported by major browser vendors.
Hybrid signature: Strong nesting with classical and PQC scheme
Our proposed implementation relies on a hybrid approach that combines the battle tested ECDSA signature algorithm and the recently standardized quantum resistant signature algorithm, Dilithium. In collaboration with ETH, we developed this novel hybrid signature schema that offers the best of both worlds. Relying on a hybrid signature is critical as the security of Dilithium and other recently standardized quantum resistant algorithms haven’t yet stood the test of time and recent attacks on Rainbow (another quantum resilient algorithm) demonstrate the need for caution. This cautiousness is particularly warranted for security keys as most can’t be upgraded – although we are working toward it for OpenSK. The hybrid approach is also used in other post-quantum efforts like Chrome’s support for TLS.
On the technical side, a large challenge was to create a Dilithium implementation small enough to run on security keys’ constrained hardware. Through careful optimization, we were able to develop a Rust memory optimized implementation that only required 20 KB of memory, which was sufficiently small enough. We also spent time ensuring that our implementation signature speed was well within the expected security keys specification. That said, we believe improving signature speed further by leveraging hardware acceleration would allow for keys to be more responsive.
Moving forward, we are hoping to see this implementation (or a variant of it), being standardized as part of the FIDO2 key specification and supported by major web browsers so that users' credentials can be protected against quantum attacks. If you are interested in testing this algorithm or contributing to security key research, head to our open source implementation OpenSK.
Chrome 106 added support for enforcing key pins on Android by default, bringing Android to parity with Chrome on desktop platforms. But what is key pinning anyway?
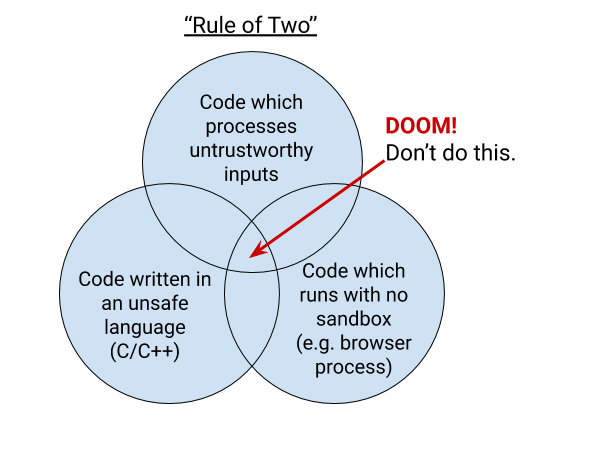
One of the reasons Chrome implements key pinning is the “rule of two”. This rule is part of Chrome’s holistic secure development process. It says that when you are writing code for Chrome, you can pick no more than two of: code written in an unsafe language, processing untrustworthy inputs, and running without a sandbox. This blog post explains how key pinning and the rule of two are related.
The Rule of Two
Chrome is primarily written in the C and C++ languages, which are vulnerable to memory safety bugs. Mistakes with pointers in these languages can lead to memory being misinterpreted. Chrome invests in an ever-stronger multi-process architecture built on sandboxing and site isolation to help defend against memory safety problems. Android-specific features can be written in Java or Kotlin. These languages are memory-safe in the common case. Similarly, we’re working on adding support to write Chrome code in Rust, which is also memory-safe.
Much of Chrome is sandboxed, but the sandbox still requires a core high-privilege “broker” process to coordinate communication and launch sandboxed processes. In Chrome, the broker is the browser process. The browser process is the source of truth that allows the rest of Chrome to be sandboxed and coordinates communication between the rest of the processes.
If an attacker is able to craft a malicious input to the browser process that exploits a bug and allows the attacker to achieve remote code execution (RCE) in the browser process, that would effectively give the attacker full control of the victim’s Chrome browser and potentially the rest of the device. Conversely, if an attacker achieves RCE in a sandboxed process, such as a renderer, the attacker's capabilities are extremely limited. The attacker cannot reach outside of the sandbox unless they can additionally exploit the sandbox itself.
Without sandboxing, which limits the actions an attacker can take, and without memory safety, which removes the ability of a bug to disrupt the intended control flow of the program, the rule of two requires that the browser process does not handle untrustworthy inputs. The relative risks between sandboxed processes and the browser process are why the browser process is only allowed to parse trustworthy inputs and specific IPC messages.
Trustworthy inputs are defined extremely strictly: A “trustworthy source” means that Chrome can prove that the data comes from Google. Effectively, this means that in situations where the browser process needs access to data from external sources, it must be read from Google servers. We can cryptographically prove that data came from Google servers if that data comes from:
The component updater and the variations framework are services specific to Chrome used to ship data-only updates and configuration information. These services both use asymmetric cryptography to authenticate their data, and the public key used to verify data sent by these services is shipped in Chrome.
However, Chrome is a feature-filled browser with many different use cases, and many different features beyond just updating itself. Certain features, such as Sign-In and the Discover Feed, need to communicate with Google. For features like this, that communication can be considered trustworthy if it comes from a pinned HTTPS server.
When Chrome connects to an HTTPS server, the server says “a 3rd party you trust (a certification authority; CA) has vouched for my identity.” It does this by presenting a certificate issued by a trusted certification authority. Chrome verifies the certificate before continuing. The modern web necessarily has a lot of CAs, all of whom can provide authentication for any website. To further ensure that the Chrome browser process is communicating with a trustworthy Google server we want to verify something more: whether a specific CA is vouching for the server. We do this by building a map of sites → expected CAs directly into Chrome. We call this key pinning. We call the map the pin set.
What is Key Pinning?
Key pinning was born as a defense against real attacks seen in the wild: attackers who can trick a CA to issue a seemingly-valid certificate for a server, and then the attacker can impersonate that server. This happened to Google in 2011, when the DigiNotar certification authority was compromised and used to issue malicious certificates for Google services. To defend against this risk, Chrome contains a pin set for all Google properties, and we only consider an HTTPS input trustworthy if it’s authenticated using a key in this pin set. This protects against malicious certificate issuance by third parties.
Key pinning can be brittle, and is rarely worth the risks. Allowing the pin set to get out of date can lead to locking users out of a website or other services, potentially permanently. Whenever pinning, it’s important to have safety-valves such as not enforcing pinning (i.e. failing open) when the pins haven't been updated recently, including a “backup” key pin, and having fallback mechanisms for bootstrapping. It's hard for individual sites to manage all of these mechanisms, which is why dynamic pinning over HTTPS (HPKP) was deprecated. Key pinning is still an important tool for some use cases, however, where there's high-privilege communication that needs to happen between a client and server that are operated by the same entity, such as web browsers, automatic software updates, and package managers.
Security Benefits of Key Pinning in Chrome, Now on Android
By pinning in Chrome, we can protect users from CA compromise. We take steps to prevent an out-of-date pinset from unnecessarily blocking users from accessing Google or Google's services. As both a browser vendor and site operator, however, we have additional tools to ensure we keep our pin sets up to date—if we use a new key or a new domain, we can add it to the pin set in Chrome at the same time. In our original implementation of pinning, the pin set is directly compiled into Chrome and updating the pin set requires updating the entire Chrome binary. To make sure that users of old versions of Chrome can still talk to Google, pinning isn't enforced if Chrome detects that it is more than 10 weeks old.
Historically, Chrome enforced the age limit by comparing the current time to the build timestamp in the Chrome binary. Chrome did not enforce pinning on Android because the build timestamp on Android wasn’t always reflective of the age of the Chrome pinset, which meant that the chance of a false positive pin mismatch was higher.
Without enforcing pins on Android, Chrome was limiting the ways engineers could build features that comply with the rule of two. To remove this limitation, we built an improved mechanism for distributing the built-in pin set to Chrome installs, including Android devices. Chrome still contains a built-in pin set compiled into the binary. However, we now additionally distribute the pin set via the component updater, which is a mechanism for Chrome to dynamically push out data-only updates to all Chrome installs without requiring a full Chrome update or restart. The component contains the latest version of the built-in pin set, as well as the certificate transparency log list and the contents of the Chrome Root Store. This means that even if Chrome is out of date, it can still receive updates to the pin set. The component also includes the timestamp the pin list was last updated, rather than relying on build timestamp. This drastically reduces the false positive risk of enabling key pinning on Android.
After we moved the pin set to component updater, we were able to do a slow rollout of pinning enforcement on Android. We determined that the false positive risk was now in line with desktop platforms, and enabled key pinning enforcement by default since Chrome 106, released in September 2022.
This change has been entirely invisible to users of Chrome. While not all of the changes we make in Chrome are flashy, we're constantly working behind the scenes to keep Chrome as secure as possible and we're excited to bring this protection to Android.
Finding and mitigating security vulnerabilities is critical to keeping Internet users safe. However, the more complex a system becomes, the harder it is to secure—and that is also the case with computing hardware and processors, which have developed highly advanced capabilities over the years. This post will detail this trend by exploring Downfall and Zenbleed, two new security vulnerabilities (one of which was disclosed today) that prior to mitigation had the potential to affect billions of personal and cloud computers, signifying the importance of vulnerability research and cross-industry collaboration. Had these vulnerabilities not been discovered by Google researchers, and instead by adversaries, they would have enabled attackers to compromise Internet users. For both vulnerabilities, Google worked closely with our partners in the industry to develop fixes, deploy mitigations and gather details to share widely and better secure the ecosystem.
Downfall (CVE-2022-40982) and Zenbleed (CVE-2023-20593) are two different vulnerabilities affecting CPUs - Intel Core (6th - 11th generation) and AMD Zen2, respectively. They allow an attacker to violate the software-hardware boundary established in modern processors. This could allow an attacker to access data in internal hardware registers that hold information belonging to other users of the system (both across different virtual machines and different processes).
These vulnerabilities arise from complex optimizations in modern CPUs that speed up applications:
Preemptive multitasking and simultaneous multithreading enable users and applications to share CPU cores, while the CPU enforces security boundaries at the architecture level to stop a malicious user accessing data from other users.
Speculative execution allows the CPU core to execute instructions from a single execution thread without waiting for prior instructions to be completed.
SIMD enables data-level parallelism where an instruction computes the same function multiple times with different data.
Downfall, affecting Intel CPUs, exploits the speculative forwarding of data from the SIMD Gather instruction. The Gather instruction helps the software access scattered data in memory quickly, which is crucial for high-performance computing workloads performing data encoding and processing. Downfall shows that this instruction forwards stale data from the internal physical hardware registers to succeeding instructions. Although this data is not directly exposed to software registers, it can trivially be extracted via similar exploitation techniques as Meltdown. Since these physical hardware register files are shared across multiple users sharing the same CPU core, an attacker can ultimately extract data from other users.
Zenbleed, affecting AMD CPUs, shows that incorrectly implemented speculative execution of the SIMD Zeroupper instruction leaks stale data from physical hardware registers to software registers. Zeroupper instructions should clear the data in the upper-half of SIMD registers (e.g., 256-bit register YMM) which on Zen2 processors is done by just setting a flag that marks the upper half of the register as zero. However, if on the same cycle as a register to register move the Zeroupper instruction is mis-speculated, the zero flag doesn’t get rolled back properly, leading to the upper-half of the YMM register to hold stale data rather than the value of zero. Similar to Downfall, leaking stale data from physical hardware registers expose the data from other users who share the same CPU core and its internal physical registers.
Downfall
Zenbleed
Affects
Intel Core (6th-11th Gen)
AMD Zen 2
Leaks
Entire XMM/YMM/ZMM Register
Upper-half of 256-bit YMM Registers
Exploit
Gather Data Sampling
Architectural Data Leak
Discovered by
Microarchitectural Analysis
Fuzzing
Fix
Microcode blocking speculative forwarding from Gather
Microcode properly wiping out YMM register when Zeroupper
Mitigation overhead
0-50% depending on the workload
Statistically insignificant
Reported on
August 24, 2022
May, 15 2023
Fixed on
August 8, 2023
July 19, 2023
Vulnerability research continues to be at the heart of our security work at Google. We invest in not only vulnerability research, but in the community as a whole in order to encourage further research that keeps all users safe. These vulnerabilities were no exception, and we worked closely with our industry partners to make them aware of the vulnerabilities, coordinate on mitigations, align on disclosure timelines and a plan to get details out to the ecosystem.
Upon disclosures, we immediately published Security Bulletins for both Downfall and Zenbleed that detailed how Google responded to each vulnerability, and provided guidance for the industry. In addition to our bulletins, we posted technical details for insights on both Downfall and Zenbleed. It’s imperative that vulnerability research continues to be supported by the industry, and we’re dedicated to doing our part to helping protect those that do this important work.
These long existing vulnerabilities, their discovery and the mitigations that followed have provided several lessons learned that will help the industry move forward in vulnerability research, including:
There are fundamental challenges in designing secure hardware that requires further research and understanding.
There are gaps in automated testing and verification of hardware for vulnerabilities.
Optimization features that are supposed to make computation faster are closely related to security and can introduce new vulnerabilities, if not implemented properly.
As Downfall and Zenbleed, suggest, computer hardware is only becoming more complex everyday, and so we will see more vulnerabilities, which is why Google is investing in CPU/hardware security research. We look forward to continuing to share our insights and encourage the wider industry to join us in helping to expand on this work.
Downfall will be presented at Blackhat USA 2023 on August 9 at 1:30pm. You can also read more about Zenbleed on this advisory.