The Domain Name System (DNS) is a fundamental protocol used on the Internet to translate human-readable domain names (e.g., www.example.com) into numeric IP addresses (e.g., 192.0.2.1) so that devices and servers can find and communicate with each other. When a user enters a domain name in their browser, the DNS resolver (e.g. Google Public DNS) locates the authoritative DNS nameservers for the requested name, and queries one or more of them to obtain the IP address(es) to return to the browser.
When DNS was launched in the early 1980s as a trusted, content-neutral infrastructure, security was not yet a pressing concern, however, as the Internet grew DNS became vulnerable to various attacks. In this post, we will look at DNS cache poisoning attacks and how Google Public DNS addresses the risks associated with them.
DNS lookups in most applications are forwarded to a caching resolver (which could be local or an open resolver like. Google Public DNS). The path from a client to the resolver is usually on a local network or can be protected using encrypted transports like DoH, DoT. The resolver queries authoritative DNS servers to obtain answers for user queries. This communication primarily occurs over UDP, an insecure connectionless protocol, in which messages can be easily spoofed including the source IP address. The content of DNS queries may be sufficiently predictable that even an off-path attacker can, with enough effort, forge responses that appear to be from the queried authoritative server. This response will be cached if it matches the necessary fields and arrives before the authentic response. This type of attack is called a cache poisoning attack, which can cause great harm once successful. According to RFC 5452, the probability of success is very high without protection. Forged DNS responses can lead to denial of service, or may even compromise application security. For an excellent introduction to cache poisoning attacks, please see “An Illustrated Guide to the Kaminsky DNS Vulnerability”.
Improving DNS security has been a goal of Google Public DNS since our launch in 2009. We take a multi-pronged approach to protect users against DNS cache-poisoning attacks. There is no silver bullet or countermeasure that entirely solves the problem, but in combination they make successful attacks substantially more difficult.
We have implemented the basic countermeasures outlined in RFC 5452 namely randomizing query source ports and query IDs. But these measures alone are not sufficient (see page 8 of our OARC 38 presentation).
We have therefore also implemented support for RFC 7873 (DNS Cookies) which can make spoofing impractical if it’s supported by the authoritative server. Measurements indicate that the DNS Cookies do not provide sufficient coverage, even though around 40% of nameservers by IP support DNS Cookies, these account for less than 10% of overall query volume. In addition, many non-compliant nameservers return incorrect or ambiguous responses for queries with DNS Cookies, which creates further deployment obstacles. For now, we’ve enabled DNS Cookies through manual configuration, primarily for selected TLD zones.
The query name case randomization mechanism, originally proposed in a March 2008 draft “Use of Bit 0x20 in DNS Labels to Improve Transaction Identity”, however, is highly effective, because all but a small minority of nameservers are compatible with query name case randomization. We have been performing case randomization of query names since 2009 to a small set of chosen nameservers that handle only a minority of our query volume.
In 2022 we started work on enabling case randomization by default, which when used, the query name in the question section is randomized and the DNS server’s response is expected to match the case-randomized query name exactly in the request. For example, if “ExaMplE.CoM” is the name sent in the request, the name in the question section of the response must also be “ExaMplE.CoM” rather than, e.g., “example.com.” Responses that fail to preserve the case of the query name may be dropped as potential cache poisoning attacks (and retried over TCP).
We are happy to announce that we’ve already enabled and deployed this feature globally by default. It covers over 90% of our UDP traffic to nameservers, significantly reducing the risk of cache poisoning attacks.
Meanwhile, we maintain an exception list and implement fallback mechanisms to prevent potential issues with non-conformant nameservers. However we strongly recommend that nameserver implementations preserve the query case in the response.
In addition to case randomization, we’ve deployed DNS-over-TLS to authoritative nameservers (ADoT), following procedures described in RFC 9539 (Unilateral Opportunistic Deployment of Encrypted Recursive-to-Authoritative DNS). Real world measurements show that ADoT has a higher success rate and comparable latency to UDP. And ADoT is in use for around 6% of egress traffic. At the cost of some CPU and memory, we get both security and privacy for nameserver queries without DNS compliance issues.
Google Public DNS takes security of our users seriously. Through multiple countermeasures to cache poisoning attacks, we aim to provide a more secure and reliable DNS resolution service, enhancing the overall Internet experience for users worldwide. With the measures described above we are able to provide protection against passive attacks for over 90% of authoritative queries.
To enhance DNS security, we recommend that DNS server operators support one or more of the security mechanisms described here. We are also working with the DNS community to improve DNS security. Please see our presentations at DNS-OARC 38 and 40 for more technical details.
With steady improvements to Android userspace and kernel security, we have noticed an increasing interest from security researchers directed towards lower level firmware. This area has traditionally received less scrutiny, but is critical to device security. We have previously discussed how we have been prioritizing firmware security, and how to apply mitigations in a firmware environment to mitigate unknown vulnerabilities.
In this post we will show how the Kernel Address Sanitizer (KASan) can be used to proactively discover vulnerabilities earlier in the development lifecycle. Despite the narrow application implied by its name, KASan is applicable to a wide-range of firmware targets. Using KASan enabled builds during testing and/or fuzzing can help catch memory corruption vulnerabilities and stability issues before they land on user devices. We've already used KASan in some firmware targets to proactively find and fix 40+ memory safety bugs and vulnerabilities, including some of critical severity.
Along with this blog post we are releasing a small project which demonstrates an implementation of KASan for bare-metal targets leveraging the QEMU system emulator. Readers can refer to this implementation for technical details while following the blog post.
Address sanitizer is a compiler-based instrumentation tool used to identify invalid memory access operations during runtime. It is capable of detecting the following classes of temporal and spatial memory safety bugs:
ASan relies on the compiler to instrument code with dynamic checks for virtual addresses used in load/store operations. A separate runtime library defines the instrumentation hooks for the heap memory and error reporting. For most user-space targets (such as aarch64-linux-android) ASan can be enabled as simply as using the -fsanitize=address compiler option for Clang due to existing support of this target both in the toolchain and in the libclang_rt runtime.
-fsanitize=address
However, the situation is rather different for bare-metal code which is frequently built with the none system targets, such as arm-none-eabi. Unlike traditional user-space programs, bare-metal code running inside an embedded system often doesn’t have a common runtime implementation. As such, LLVM can’t provide a default runtime for these environments.
none
arm-none-eabi
To provide custom implementations for the necessary runtime routines, the Clang toolchain exposes an interface for address sanitization through the -fsanitize=kernel-address compiler option. The KASan runtime routines implemented in the Linux kernel serve as a great example of how to define a KASan runtime for targets which aren’t supported by default with -fsanitize=address. We'll demonstrate how to use the version of address sanitizer originally built for the kernel on other bare-metal targets.
-fsanitize=kernel-address
Let’s take a look at the KASan major building blocks from a high-level perspective (a thorough explanation of how ASan works under-the-hood is provided in this whitepaper).
The main idea behind KASan is that every memory access operation, such as load/store instructions and memory copy functions (for example, memmove and memcpy), are instrumented with code which performs verification of the destination/source memory regions. KASan only allows the memory access operations which use valid memory regions. When KASan detects memory access to a memory region which is invalid (that is, the memory has been already freed or access is out-of-bounds) then it reports this violation to the system.
memmove
memcpy
The state of memory regions covered by KASan is maintained in a dedicated area called shadow memory. Every byte in the shadow memory corresponds to a single fixed-size memory region covered by KASan (typically 8-bytes) and encodes its state: whether the corresponding memory region has been allocated or freed and how many bytes in the memory region are accessible.
Therefore, to enable KASan for a bare-metal target we would need to implement the instrumentation routines which verify validity of memory regions in memory access operations and report KASan violations to the system. In addition we would also need to implement shadow memory management to track the state of memory regions which we want to be covered with KASan.
The very first step in enabling KASan for firmware is to reserve a sufficient amount of DRAM for shadow memory. This is a memory region where each byte is used by KASan to track the state of an 8-byte region. This means accommodating the shadow memory requires a dedicated memory region equal to 1/8th the size of the address space covered by KASan.
KASan maps every 8-byte aligned address from the DRAM region into the shadow memory using the following formula:
shadow_address = (target_address >> 3 ) + shadow_memory_base where target_address is the address of a 8-byte memory region which we want to cover with KASan and shadow_memory_base is the base address of the shadow memory area.
Once we have the shadow memory tracking the state of every single 8-byte memory region of DRAM we need to implement the necessary runtime routines which KASan instrumentation depends on. For reference, a comprehensive list of runtime routines needed for KASan can be found in the linux/mm/kasan/kasan.h Linux kernel header. However, it might not be necessary to implement all of them and in the following text we focus on the ones which were needed to enable KASan for our target firmware as an example.
The routines __asan_loadXX_noabort, __asan_storeXX_noabort perform verification of memory access at runtime. The symbol XX denotes size of memory access and goes as a power of 2 starting from 1 up to 16. The toolchain instruments every memory load and store operations with these functions so that they are invoked before the memory access operation happens. These routines take as input a pointer to the target memory region to check it against the shadow memory.
__asan_loadXX_noabort
__asan_storeXX_noabort
XX
If the region state provided by shadow memory doesn’t reveal a violation, then these functions return to the caller. But if any violations (for example, the memory region is accessed after it has been deallocated or there is an out-of-bounds access) are revealed, then these functions report the KASan violation by:
The routine __asan_set_shadow_YY is used to poison shadow memory for a given address. This routine is used by the toolchain instrumentation to update the state of memory regions. For example, the KASan runtime would use this function to mark memory for local variables on the stack as accessible/poisoned in the epilogue/prologue of the function respectively.
__asan_set_shadow_YY
This routine takes as input a target memory address and sets the corresponding byte in shadow memory to the value of YY. Here is an example of some YY values for shadow memory to encode state of 8-byte memory regions:
YY
The routines __asan_register_globals, __asan_unregister_globals are used to poison/unpoison memory for global variables. The KASan runtime calls these functions while processing global constructors/destructors. For instance, the routine __asan_register_globals is invoked for every global variable. It takes as an argument a pointer to a data structure which describes the target global variable: the structure provides the starting address of the variable, its size not including the red zone and size of the global variable with the red zone.
__asan_register_globals
__asan_unregister_globals
The red zone is extra padding the compiler inserts after the variable to increase the likelihood of detecting an out-of-bounds memory access. Red zones ensure there is extra space between adjacent global variables. It is the responsibility of __asan_register_globals routine to mark the corresponding shadow memory as accessible for the variable and as poisoned for the red zone.
As the readers could infer from its name, the routine __asan_unregister_globals is invoked while processing global destructors and is intended to poison shadow memory for the target global variable. As a result, any memory access to such a global will cause a KASan violation.
The KASan compiler instrumentation routines __asan_loadXX_noabort, __asan_storeXX_noabort discussed above are used to verify individual memory load and store operations such as, reading or writing an array element or dereferencing a pointer. However, these routines don't cover memory access in bulk-memory copy functions such as memcpy, memmove, and memset. In many cases these functions are provided by the runtime library or implemented in assembly to optimize for performance.
memset
Therefore, in order to be able to catch invalid memory access in these functions, we would need to provide sanitized versions of memcpy, memmove, and memset functions in our KASan implementation which would verify memory buffers to be valid memory regions.
memmove,
Another routine required by KASan is __asan_handle_no_return, to perform cleanup before a noreturn function and avoid false positives on the stack. KASan adds red zones around stack variables at the start of each function, and removes them at the end. If a function does not return normally (for example, in case of longjmp-like functions and exception handling), red zones must be removed explicitly with __asan_handle_no_return.
__asan_handle_no_return
noreturn
longjmp
Bare-metal code in the vast majority of cases provides its own heap implementation. It is our responsibility to implement an instrumented version of heap memory allocation and freeing routines which enable KASan to detect memory corruption bugs on the heap.
Essentially, we would need to instrument the memory allocator with the code which unpoisons KASan shadow memory corresponding to the allocated memory buffer. Additionally, we may want to insert an extra poisoned red zone memory (which accessing would then generate a KASan violation) to the end of the allocated buffer to increase the likelihood of catching out-of-bounds memory reads/writes.
Similarly, in the memory deallocation routine (such as free) we would need to poison the shadow memory corresponding to the free buffer so that any subsequent access (such as, use-after-free) would generate a KASan violation.
free
We can go even further by placing the freed memory buffer into a quarantine instead of immediately returning the free memory back to the allocator. This way, the freed memory buffer is suspended in quarantine for some time and will have its KASan shadow bytes poisoned for a longer period of time, increasing the probability of catching a use-after-free access to this buffer.
With all the necessary building blocks implemented we are ready to enable KASan for our bare-metal code by applying the following compiler options while building the target with the LLVM toolchain.
The -fsanitize=kernel-address Clang option instructs the compiler to instrument memory load/store operations with the KASan verification routines.
We use the -asan-mapping-offset LLVM option to indicate where we want our shadow memory to be located. For instance, let’s assume that we would like to cover address range 0x40000000 - 0x4fffffff and we want to keep shadow memory at address 0x4A700000. So, we would use -mllvm -asan-mapping-offset=0x42700000 as 0x40000000 >> 3 + 0x42700000 == 0x4A700000.
To cover globals and stack variables with KASan we would need to pass additional options to the compiler: -mllvm -asan-stack=1 -mllvm -asan-globals=1. It’s worth mentioning that instrumenting both globals and stack variables will likely result in an increase in size of the corresponding memory which might need to be accounted for in the linker script.
Finally, to prevent significant increase in size of the code section due to KASan instrumentation we instruct the compiler to always outline KASan checks using the -mllvm -asan-instrumentation-with-call-threshold=0 option. Otherwise, the compiler might inline
__asan_loadXX_noabort, __asan_storeXX_noabort routines for load/store operations resulting in bloating the generated object code.
__asan_loadXX_noabort, __asan_storeXX_noabort
LLVM has traditionally only supported sanitizers with runtimes for specific targets with predefined runtimes, however we have upstreamed LLVM sanitizer support for bare-metal targets under the assumption that the runtime can be defined for the particular target. You’ll need the latest version of Clang to benefit from this.
Following these steps we managed to enable KASan for a firmware target and use it in pre-production test builds. This led to early discovery of memory corruption issues that were easily remediated due to the actionable reports produced by KASan. These builds can be used with fuzzers to detect edge case bugs that normal testing fails to trigger, yet which can have significant security implications.
Our work with KASan is just one example of the multiple techniques the Android team is exploring to further secure bare-metal firmware in the Android Platform. Ideally we want to avoid introducing memory safety vulnerabilities in the first place so we are working to address this problem through adoption of memory-safe Rust in bare-metal environments. The Android team has developed Rust training which covers bare-metal Rust extensively. We highly encourage others to explore Rust (or other memory-safe languages) as an alternative to C/C++ in their firmware.
If you have any questions, please reach out – we’re here to help!
Acknowledgements: Thank you to Roger Piqueras Jover for contributions to this post, and to Evgenii Stepanov for upstreaming LLVM support for bare-metal sanitizers. Special thanks also to our colleagues who contribute and support our firmware security efforts: Sami Tolvanen, Stephan Somogyi, Stephan Chen, Dominik Maier, Xuan Xing, Farzan Karimi, Pirama Arumuga Nainar, Stephen Hines.
For more than 15 years, Google Safe Browsing has been protecting users from phishing, malware, unwanted software and more, by identifying and warning users about potentially abusive sites on more than 5 billion devices around the world. As attackers grow more sophisticated, we've seen the need for protections that can adapt as quickly as the threats they defend against. That’s why we're excited to announce a new version of Safe Browsing that will provide real-time, privacy-preserving URL protection for people using the Standard protection mode of Safe Browsing in Chrome.
Chrome automatically protects you by flagging potentially dangerous sites and files, hand in hand with Safe Browsing which discovers thousands of unsafe sites every day and adds them to its lists of harmful sites and files.
So far, for privacy and performance reasons, Chrome has first checked sites you visit against a locally-stored list of known unsafe sites which is updated every 30 to 60 minutes – this is done using hash-based checks.
Hash-based check overview
But unsafe sites have adapted — today, the majority of them exist for less than 10 minutes, meaning that by the time the locally-stored list of known unsafe sites is updated, many have slipped through and had the chance to do damage if users happened to visit them during this window of opportunity. Further, Safe Browsing’s list of harmful websites continues to grow at a rapid pace. Not all devices have the resources necessary to maintain this growing list, nor are they always able to receive and apply updates to the list at the frequency necessary to benefit from full protection.
Safe Browsing’s Enhanced protection mode already stays ahead of such threats with technologies such as real-time list checks and AI-based classification of malicious URLs and web pages. We built this mode as an opt-in to give users the choice of sharing more security-related data in order to get stronger security. This mode has shown that checking lists in real time brings significant value, so we decided to bring that to the default Standard protection mode through a new API – one that doesn't share the URLs of sites you visit with Google.
In order to transition to real-time protection, checks now need to be performed against a list that is maintained on the Safe Browsing server. The server-side list can include unsafe sites as soon as they are discovered, so it is able to capture sites that switch quickly. It can also grow as large as needed because the Safe Browsing server is not constrained in the same way that user devices are.
Behind the scenes, here's what is happening in Chrome:
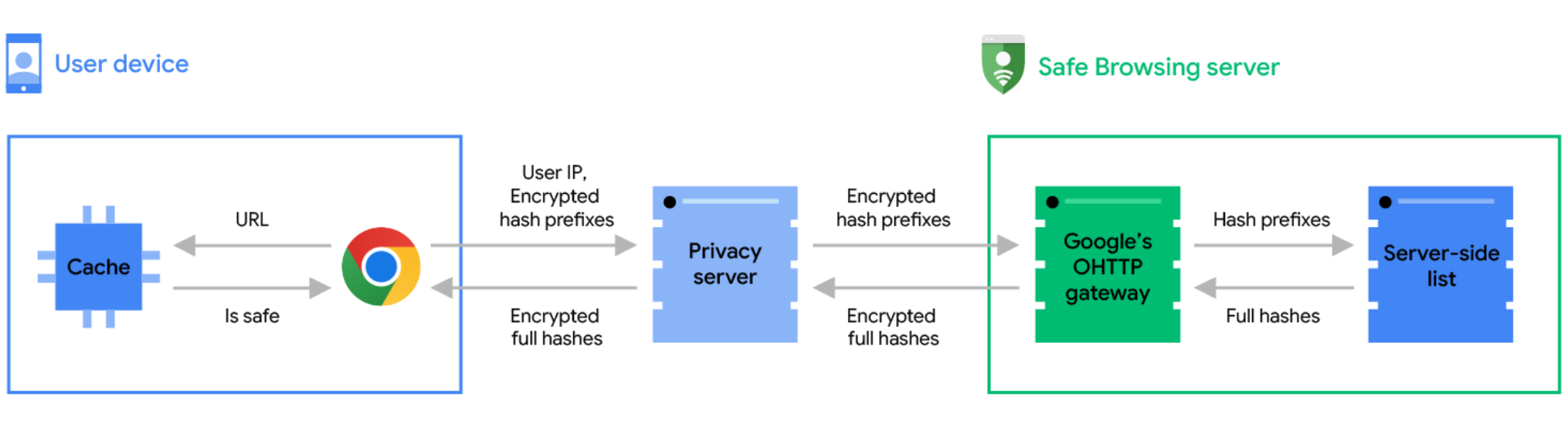
In order to preserve user privacy, we have partnered with Fastly, an edge cloud platform that provides content delivery, edge compute, security, and observability services, to operate an Oblivious HTTP (OHTTP) privacy server between Chrome and Safe Browsing – you can learn more about Fastly's commitment to user privacy on their Customer Trust page. With OHTTP, Safe Browsing does not see your IP address, and your Safe Browsing checks are mixed amongst those sent by other Chrome users. This means Safe Browsing cannot correlate the URL checks you send as you browse the web.
Before hash prefixes leave your device, Chrome encrypts them using a public key from Safe Browsing. These encrypted hash prefixes are then sent to the privacy server. Since the privacy server doesn’t know the private key, it cannot decrypt the hash prefixes, which offers privacy from the privacy server itself.
The privacy server then removes potential user identifiers such as your IP address and forwards the encrypted hash prefixes to the Safe Browsing server. The privacy server is operated independently by Fastly, meaning that Google doesn’t have access to potential user identifiers (including IP address and User Agent) from the original request. Once the Safe Browsing server receives the encrypted hash prefixes from the privacy server, it decrypts the hash prefixes with its private key and then continues to check the server-side list.
Ultimately, Safe Browsing sees the hash prefixes of your URL but not your IP address, and the privacy server sees your IP address but not the hash prefixes. No single party has access to both your identity and the hash prefixes. As such, your browsing activity remains private.
Real-time check overview
Compared with the hash-based check, the real-time check requires sending a request to a server, which adds additional latency. We have employed a few techniques to make sure your browsing experience continues to be smooth and responsive.
First, before performing the real-time check, Chrome checks against a global and local cache on your device to avoid unnecessary delay.
Both caches are stored in memory, so it is much faster to check them than sending a real-time request over the network.
In addition, Chrome follows a fallback mechanism in case of unsuccessful or slow requests. If the real-time request fails consecutively, Chrome will enter a back-off mode and downgrade the checks to hash-based checks for a certain period.
We are also in the process of introducing an asynchronous mechanism, which will allow the site to load while the real-time check is in progress. This will improve the user experience, as the real-time check won’t block page load.
With the latest release of Chrome for desktop, Android, and iOS, we’re upgrading the Standard protection mode of Safe Browsing so it will now check sites using Safe Browsing’s real-time protection protocol, without sharing your browsing history with Google. You don't need to take any action to benefit from this improved functionality.
If you want more protection, we still encourage you to turn on the Enhanced protection mode of Safe Browsing. You might wonder why you need enhanced protection when you'll be getting real-time URL protection in Standard protection – this is because in Standard protection mode, the real-time feature can only protect you from sites that Safe Browsing has already confirmed to be unsafe. On the other hand, Enhanced protection mode is able to use additional information together with advanced machine learning models to protect you from sites that Safe Browsing may not yet have confirmed to be unsafe, for example because the site was only very recently created or is cloaking its true behavior to Safe Browsing’s detection systems.
Enhanced protection also continues to offer protection beyond real-time URL checks, for example by providing deep scans for suspicious files and extra protection from suspicious Chrome extensions.
The real-time feature of the Standard protection mode of Safe Browsing is on by default for Chrome. If needed, it may be configured using the policy SafeBrowsingProxiedRealTimeChecksAllowed. It is also worth noting that in order for this feature to work in Chrome, enterprises may need to explicitly allow traffic to the Fastly privacy server. If the server is not reachable, Chrome will downgrade the checks to hash-based checks.
While Chrome is the first surface where these protections are available, we plan to make them available to eligible developers for non-commercial use cases via the Safe Browsing API. Using the API, developers and privacy server operators can partner to better protect their products’ users from fast-moving malicious actors in a privacy-preserving manner. To learn more, keep an eye out for our upcoming developer documentation to be published on the Google for Developers site.
Last year, we again witnessed the power of community-driven security efforts as researchers from around the world contributed to help us identify and address thousands of vulnerabilities in our products and services. Working with our dedicated bug hunter community, we awarded $10 million to our 600+ researchers based in 68 countries.
New Resources and Improvements
Just like every year, 2023 brought a series of changes and improvements to our vulnerability reward programs:
As in past years, we are sharing our 2023 Year in Review statistics across all of our programs. We would like to give a special thank you to all of our dedicated researchers for their continued work with our programs - we look forward to more collaboration in the future!
Android and Google Devices
In 2023, the Android VRP achieved significant milestones, reflecting our dedication to securing the Android ecosystem. We awarded over $3.4 million in rewards to researchers who uncovered remarkable vulnerabilities within Android and increased our maximum reward amount to $15,000 for critical vulnerabilities. We also saw a sharpened focus on higher severity issues as a result of our changes to incentivize report quality and increasing rewards for high and critical severity issues.
Expanding our program’s scope, Wear OS has been added to the program to further incentivize research in new wearable technology to ensure users’ safety.
Working closely with top researchers at the ESCAL8 conference, we also hosted a live hacking event for Wear OS and Android Automotive OS which resulted in $70,000 rewarded to researchers for finding over 20 critical vulnerabilities!
We would also like to spotlight the hardwear.io security conferences. Hardwear.io gave us a platform to engage with top hardware security researchers who uncovered over 50 vulnerabilities in Nest, Fitbit, and Wearables, and received a total of $116,000 last year!
The Google Play Security Reward Program continued to foster security research across popular Android apps on Google Play.
A huge thank you to the researchers who made our program such a success. A special shout out to Zinuo Han (@ele7enxxh) of OPPO Amber Security Lab and Yu-Cheng Lin (林禹成) (@AndroBugs) for your hard work and continuing to be some of the top researchers contributing to Android VRPs!
Chrome
2023 was a year of changes and experimentation for the Chrome VRP. In Chrome Milestone 116, MiraclePtr was launched across all Chrome platforms. This resulted in raising the difficulty of discovery of fully exploitable non-renderer UAFs in Chrome and resulted in lower reward amounts for MiraclePtr-protected UAFs, as highly mitigated security bugs. While code and issues protected by MiraclePtr are expected to be resilient to the exploitation of non-renderer UAFs, the Chrome VRP launched the MiraclePtr Bypass Reward to incentivize research toward discovering potential bypasses of this protection.
The Chrome VRP also launched the Full Chain Exploit Bonus, offering triple the standard full reward amount for the first Chrome full-chain exploit reported and double the standard full reward amount for any follow-up reports. While both of these large incentives have gone unclaimed, we are leaving the door open in 2024 for any researchers looking to take on these challenges.
In 2023, Chrome VRP also introduced increased rewards for V8 bugs in older channels of Chrome, with an additional bonus for bugs existing before M105. This resulted in a few very impactful reports of long-existing V8 bugs, including one report of a V8 JIT optimization bug in Chrome since at least M91, which resulted in a $30,000 reward for that researcher.
All of this resulted in $2.1M in rewards to security researchers for 359 unique reports of Chrome Browser security bugs. We were also able to meet some of our top researchers from previous years who were invited to participate in bugSWAT as part of Google’s ESCAL8 event in Tokyo in October. We capped off the year by publicly announcing our 2023 Top 20 Chrome VRP reporters who received a bonus reward for their contributions.
Thank you to the Chrome VRP security researcher community for your contributions and efforts to help us make Chrome more secure for everyone!
Generative AI
Last year, we also ran a bugSWAT live-hacking event targeting LLM products. Apart from fun, sun, and a lot to do, we also got 35 reports, totaling more than $87,000 - and discovered issues like Johann, Joseph, and Kai’s “Hacking Google Bard - From Prompt Injection to Data Exfiltration” and Roni, Justin, and Joseph’s “We Hacked Google A.I. for $50,000”.
To help AI-focused bughunters know what’s in scope and what’s not, we recently published our criteria for bugs in AI products. This criteria aims to facilitate testing for traditional security vulnerabilities as well as risks specific to AI systems, and is one way that we are implementing the voluntary AI commitments that Google made at the White House in July.
Looking Forward
We remain committed to fostering collaboration, innovation, and transparency with the security community. Our ongoing mission is to stay ahead of emerging threats, adapt to evolving technologies, and continue to strengthen the security posture of Google’s products and services. We look forward to continuing to drive greater advancements in the world of cybersecurity.
A huge thank you to our bug hunter community for helping to make Google products and platforms more safe and secure for our users around the world!
Thank you to Adam Bacchus, Dirk Göhmann, Eduardo Vela, Sarah Jacobus, Amy Ressler, Martin Straka, Jan Keller, Tony Mendez.
Google’s Project Zero reports that memory safety vulnerabilities—security defects caused by subtle coding errors related to how a program accesses memory—have been "the standard for attacking software for the last few decades and it’s still how attackers are having success". Their analysis shows two thirds of 0-day exploits detected in the wild used memory corruption vulnerabilities. Despite substantial investments to improve memory-unsafe languages, those vulnerabilities continue to top the most commonly exploited vulnerability classes.
In this post, we share our perspective on memory safety in a comprehensive whitepaper. This paper delves into the data, challenges of tackling memory unsafety, and discusses possible approaches for achieving memory safety and their tradeoffs. We'll also highlight our commitments towards implementing several of the solutions outlined in the whitepaper, most recently with a $1,000,000 grant to the Rust Foundation, thereby advancing the development of a robust memory-safe ecosystem.
2022 marked the 50th anniversary of memory safety vulnerabilities. Since then, memory safety risks have grown more obvious. Like others', Google's internal vulnerability data and research show that memory safety bugs are widespread and one of the leading causes of vulnerabilities in memory-unsafe codebases. Those vulnerabilities endanger end users, our industry, and the broader society. We're encouraged to see governments also taking this issue seriously, as with the U.S. Office of the National Cyber Director publication of a paper on the topic last week.
By sharing our insights and experiences, we hope to inspire the broader community and industry to adopt memory-safe practices and technologies, ultimately making technology safer.
At Google, we have decades of experience addressing, at scale, large classes of vulnerabilities that were once similarly prevalent as memory safety issues. Our approach, which we call “Safe Coding”, treats vulnerability-prone coding constructs themselves as hazards (i.e., independently of, and in addition to, the vulnerability they might cause), and is centered around ensuring developers do not encounter such hazards during regular coding practice.
Based on this experience, we expect that high assurance memory safety can only be achieved via a Secure-by-Design approach centered around comprehensive adoption of languages with rigorous memory safety guarantees. As a consequence, we are considering a gradual transition towards memory-safe languages like Java, Go, and Rust.
Over the past decades, in addition to large Java and Go memory-safe codebases, Google has developed and accumulated hundreds of millions of lines of C++ code that is in active use and under active, ongoing development. This very large existing codebase results in significant challenges for a transition to memory safety:
We see no realistic path for an evolution of C++ into a language with rigorous memory safety guarantees that include temporal safety.
A large-scale rewrite of all existing C++ code into a different, memory-safe language appears very difficult and will likely remain impractical.
We consider it important to complement a transition to memory safe languages for new code and particularly at-risk components with safety improvements for existing C++ code, to the extent practicable. We believe that substantial improvements can be achieved through an incremental transition to a partially-memory-safe C++ language subset, augmented with hardware security features when available. For instance, see our work improving spatial safety in GCP's networking stack.
We are actively investing in many of the solutions outlined in our whitepaper and in our response to the US Federal Government’s RFI on Open Source Software Security.
Android has written several components in Rust over the last few years, leading to compelling security improvements. In Android’s Ultra-wideband (UWB) module, this has improved the security of the module while also reducing the memory usage and inter-procedural calls.
Chrome has started shipping some features in Rust; in one case, Chrome was able to move its QR code generator out of a sandbox by adopting a new memory-safe library written in Rust, leading to both better security and better performance.
Google recently announced a $1,000,000 grant to the Rust foundation to enhance interoperability with C++ code. This will facilitate incremental adoption of Rust in existing memory-unsafe code bases, which will be key to enabling even more new development to occur in a memory-safe language. Relatedly, we are also working on addressing cross-language attacks that can occur when mixing Rust and C++ in the same binary.
Google is investing in building the memory-safe open-source ecosystem through ISRG Prossimo and OpenSSF’s Alpha-Omega project. Back in 2021, we funded efforts to bring Rust to the Linux Kernel, which is now enabling us to write memory-safe drivers. This funding is also going towards providing alternatives or upgrades to key open-source libraries in a memory-safe language, such as providing a memory safe TLS implementation.
We know that memory safe languages will not address every security bug, but just as our efforts to eliminate XSS attacks through tooling showed, removing large classes of exploits both directly benefits consumers of software and allows us to move our focus to addressing further classes of security vulnerabilities.
To access the full whitepaper and learn more about Google's perspective on memory safety, visit https://research.google/pubs/secure-by-design-googles-perspective-on-memory-safety/