Supply chain security is at the fore of the industry’s collective consciousness. We’ve recently seen a significant rise in software supply chain attacks, a Log4j vulnerability of catastrophic severity and breadth, and even an Executive Order on Cybersecurity.
It is against this background that Google is seeking contributors to a new open source project called GUAC (pronounced like the dip). GUAC, or Graph for Understanding Artifact Composition, is in the early stages yet is poised to change how the industry understands software supply chains. GUAC addresses a need created by the burgeoning efforts across the ecosystem to generate software build, security, and dependency metadata. True to Google’s mission to organize and make the world’s information universally accessible and useful, GUAC is meant to democratize the availability of this security information by making it freely accessible and useful for every organization, not just those with enterprise-scale security and IT funding.
Thanks to community collaboration in groups such as OpenSSF, SLSA, SPDX, CycloneDX, and others, organizations increasingly have ready access to:
These data are useful on their own, but it’s difficult to combine and synthesize the information for a more comprehensive view. The documents are scattered across different databases and producers, are attached to different ecosystem entities, and cannot be easily aggregated to answer higher-level questions about an organization’s software assets.
To help address this issue we’ve teamed up with Kusari, Purdue University, and Citi to create GUAC, a free tool to bring together many different sources of software security metadata. We’re excited to share the project’s proof of concept, which lets you query a small dataset of software metadata including SLSA provenance, SBOMs, and OpenSSF Scorecards.
Graph for Understanding Artifact Composition (GUAC) aggregates software security metadata into a high fidelity graph database—normalizing entity identities and mapping standard relationships between them. Querying this graph can drive higher-level organizational outcomes such as audit, policy, risk management, and even developer assistance.
Conceptually, GUAC occupies the “aggregation and synthesis” layer of the software supply chain transparency logical model:
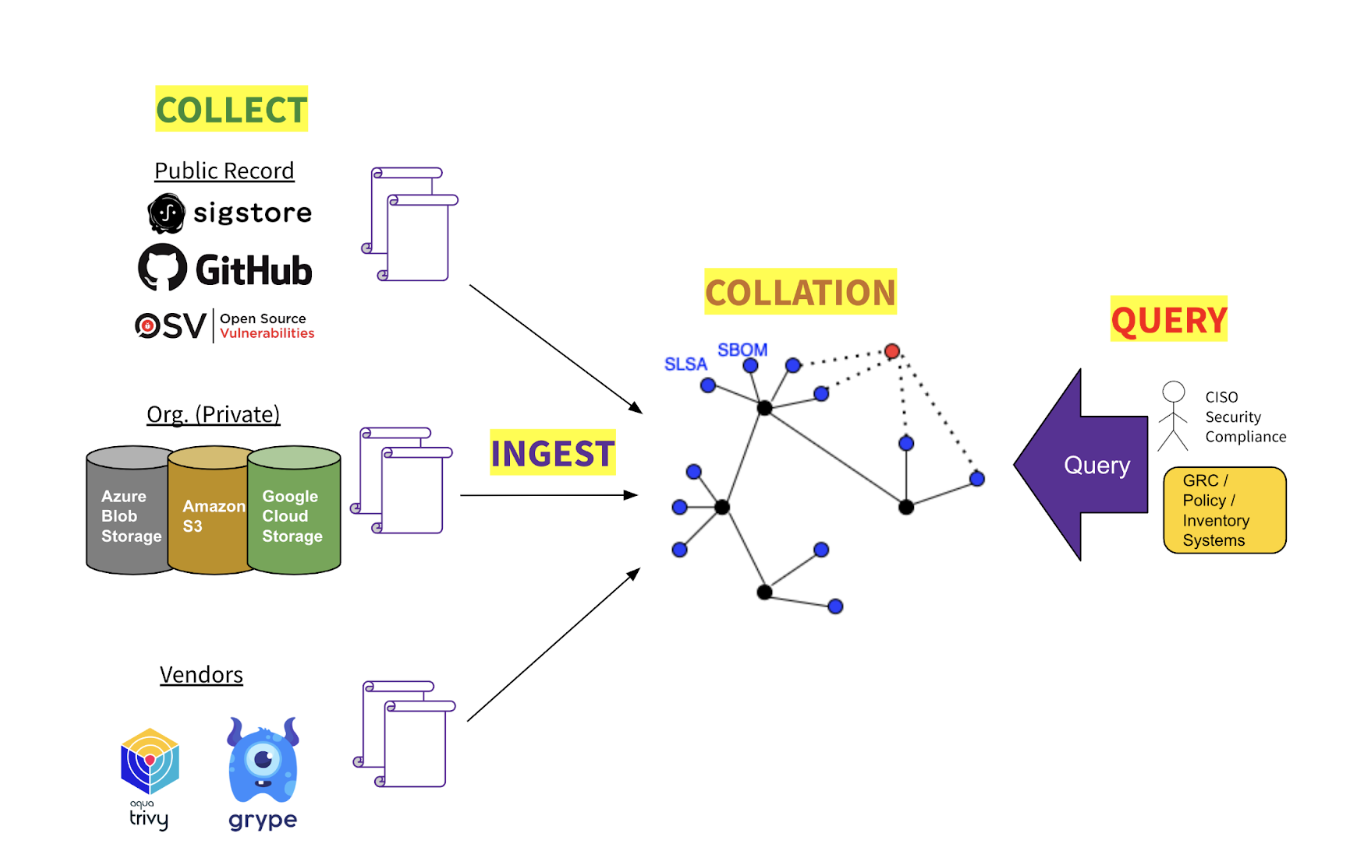
GUAC has four major areas of functionality:
A CISO or compliance officer in an organization wants to be able to reason about the risk of their organization. An open source organization like the Open Source Security Foundation wants to identify critical libraries to maintain and secure. Developers need richer and more trustworthy intelligence about the dependencies in their projects.
The good news is, increasingly one finds the upstream supply chain already enriched with attestations and metadata to power higher-level reasoning and insights. The bad news is that it is difficult or impossible today for software consumers, operators, and administrators to gather this data into a unified view across their software assets.
To understand something complex like the blast radius of a vulnerability, one needs to trace the relationship between a component and everything else in the portfolio—a task that could span thousands of metadata documents across hundreds of sources. In the open source ecosystem, the number of documents could reach into the millions.
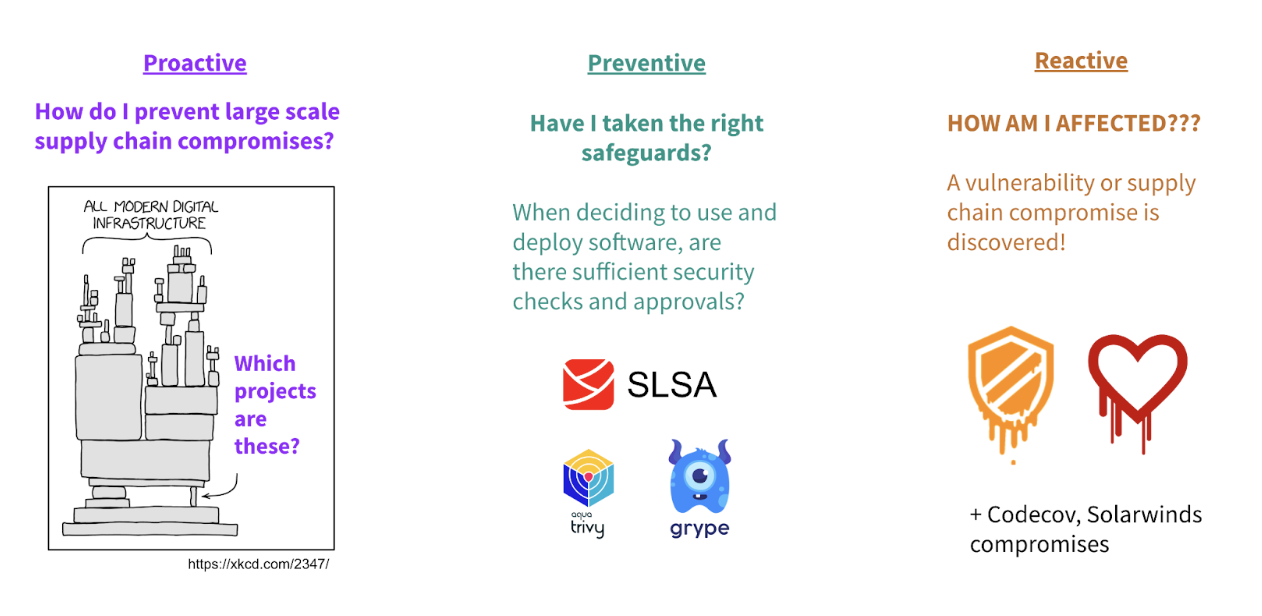
GUAC aggregates and synthesizes software security metadata at scale and makes it meaningful and actionable. With GUAC in hand, we will be able to answer questions at three important stages of software supply chain security:
Get Involved
GUAC is an Open Source project on Github, and we are excited to get more folks involved and contributing (read the contributor guide to get started)! The project is still in its early stages, with a proof of concept that can ingest SLSA, SBOM, and Scorecard documents and support simple queries and exploration of software metadata. The next efforts will focus on scaling the current capabilities and adding new document types for ingestion. We welcome help and contributions of code or documentation.
Since the project will be consuming documents from many different sources and formats, we have put together a group of “Technical Advisory Members'' to help advise the project. These members include representation from companies and groups such as SPDX, CycloneDX Anchore, Aquasec, IBM, Intel, and many more. If you’re interested in participating as a contributor or advisor representing end users’ needs—or the sources of metadata GUAC consumes—you can register your interest in the relevant GitHub issue.
The GUAC team will be showcasing the project at Kubecon NA 2022 next week. Come by our session if you’ll be there and have a chat with us—we’d be happy to talk in person or virtually!
コメントを投稿




0 件のコメント :
コメントを投稿