Chromium's sandboxed process model defends well from malicious web content, but there are limits to how well the application can protect itself from malware already on the computer. Cookies and other credentials remain a high value target for attackers, and we are trying to tackle this ongoing threat in multiple ways, including working on web standards like DBSC that will help disrupt the cookie theft industry since exfiltrating these cookies will no longer have any value.
Where it is not possible to prevent the theft of credentials and cookies by malware, the next best thing is making the attack more observable by antivirus, endpoint detection agents, or enterprise administrators with basic log analysis tools.
This blog describes one set of signals for use by system administrators or endpoint detection agents that should reliably flag any access to the browser’s protected data from another application on the system. By increasing the likelihood of an attack being detected, this changes the calculus for those attackers who might have a strong desire to remain stealthy, and might cause them to rethink carrying out these types of attacks against our users.
Background
Chromium based browsers on Windows use the DPAPI (Data Protection API) to secure local secrets such as cookies, password etc. against theft. DPAPI protection is based on a key derived from the user's login credential and is designed to protect against unauthorized access to secrets from other users on the system, or when the system is powered off. Because the DPAPI secret is bound to the logged in user, it cannot protect against local malware attacks — malware executing as the user or at a higher privilege level can just call the same APIs as the browser to obtain the DPAPI secret.
Since 2013, Chromium has been applying the CRYPTPROTECT_AUDIT flag to DPAPI calls to request that an audit log be generated when decryption occurs, as well as tagging the data as being owned by the browser. Because all of Chromium's encrypted data storage is backed by a DPAPI-secured key, any application that wishes to decrypt this data, including malware, should always reliably generate a clearly observable event log, which can be used to detect these types of attacks.
There are three main steps involved in taking advantage of this log:
This blog will also show how the logging works in practice by testing it against a python password stealer.
Step 1: Enable logging on the system
DPAPI events are logged into two places in the system. Firstly, there is the 4693 event that can be logged into the Security Log. This event can be enabled by turning on "Audit DPAPI Activity" and the steps to do this are described here, the policy itself sits deep within Security Settings -> Advanced Audit Policy Configuration -> Detailed Tracking.
Here is what the 4693 event looks like:
The issue with the 4693 event is that while it is generated if there is DPAPI activity on the system, it unfortunately does not contain information about which process was performing the DPAPI activity, nor does it contain information about which particular secret is being accessed. This is because the Execution ProcessID field in the event will always be the process id of lsass.exe because it is this process that manages the encryption keys for the system, and there is no entry for the description of the data.
It was for this reason that, in recent versions of Windows a new event type was added to help identify the process making the DPAPI call directly. This event was added to the Microsoft-Windows-Crypto-DPAPI stream which manifests in the Event Log in the Applications and Services Logs > Microsoft > Windows > Crypto-DPAPI part of the Event Viewer tree.
The new event is called DPAPIDefInformationEvent and has id 16385, but unfortunately is only emitted to the Debug channel and by default this is not persisted to an Event Log, unless Debug channel logging is enabled. This can be accomplished by enabling it directly in powershell:
Once this log is enabled then you should start to see 16385 events generated, and these will contain the real process ids of applications performing DPAPI operations. Note that 16385 events are emitted by the operating system even for data not flagged with CRYPTPROTECT_AUDIT, but to identify the data as owned by the browser, the data description is essential. 16385 events are described later.
You will also want to enable Audit Process Creation in order to be able to know a current mapping of process ids to process names — more details on that later. You might want to also consider enabling logging of full command lines.
Step 2: Collect the events
The events you want to collect are:
These should be collected from all workstations, and persisted into your enterprise logging system for analysis.
Step 3: Write detection logic to detect theft.
With these two events is it now possible to detect when an unauthorized application calls into DPAPI to try and decrypt browser secrets.
The general approach is to generate a map of process ids to active processes using the 4688 events, then every time a 16385 event is generated, it is possible to identify the currently running process, and alert if the process does not match an authorized application such as Google Chrome. You might find your enterprise logging software can already keep track of which process ids map to which process names, so feel free to just use that existing functionality.
Let's dive deeper into the events.
A 4688 event looks like this - e.g. here is Chrome browser launching from explorer:
The important part here is the NewProcessId, in hex 0x17eac which is 97964.
A 16385 event looks like this:
The important parts here are the OperationType, the DataDescription and the CallerProcessID.
For DPAPI decrypts, the OperationType will be SPCryptUnprotect.
Each Chromium based browser will tag its data with the product name, e.g. Google Chrome, or Microsoft Edge depending on the owner of the data. This will always appear in the DataDescription field, so it is possible to distinguish browser data from other DPAPI secured data.
Finally, the CallerProcessID will map to the process performing the decryption. In this case, it is 97964 which matches the process ID seen in the 4688 event above, showing that this was likely Google Chrome decrypting its own data! Bear in mind that since these logs only contain the path to the executable, for a full assurance that this is actually Chrome (and not malware pretending to be Chrome, or malware injecting into Chrome), additional protections such as removing administrator access, and application allowlisting could also be used to give a higher assurance of this signal. In recent versions of Chrome or Edge, you might also see logs of decryptions happening in the elevation_service.exe process, which is another legitimate part of the browser's data storage.
To detect unauthorized DPAPI access, you will want to generate a running map of all processes using 4688 events, then look for 16385 events that have a CallerProcessID that does not match a valid caller – Let's try that now.
Testing with a python password stealer
We can test that this works with a public script to decrypt passwords taken from a public blog. It generates two events, as expected:
Here is the 16385 event, showing that a process is decrypting the "Google Chrome" key.
Since the data description being decrypted was "Google Chrome" we know this is an attempt to read Chrome secrets, but to determine the process behind 68768 (0x10ca0), we need to correlate this with a 4688 event.
Here is the corresponding 4688 event from the Security Log (a process start for python3.exe) with the matching process id:
In this case, the process id matches the python3 executable running a potentially malicious script, so we know this is likely very suspicious behavior, and should trigger an alert immediately! Bear in mind process ids on Windows are not unique so you will want to make sure you use the 4688 event with the timestamp closest, but earlier than, the 16385 event.
Summary
This blog has described a technique for strong detection of cookie and credential theft. We hope that all defenders find this post useful. Thanks to Microsoft for adding the DPAPIDefInformationEvent log type, without which this would not be possible.
A safe and trusted Google Play experience is our top priority. We leverage our SAFE (see below) principles to provide the framework to create that experience for both users and developers. Here's what these principles mean in practice:
With those principles in mind, we’ve made recent improvements and introduced new measures to continue to keep Google Play’s users safe, even as the threat landscape continues to evolve. In 2023, we prevented 2.28 million policy-violating apps from being published on Google Play1 in part thanks to our investment in new and improved security features, policy updates, and advanced machine learning and app review processes. We have also strengthened our developer onboarding and review processes, requiring more identity information when developers first establish their Play accounts. Together with investments in our review tooling and processes, we identified bad actors and fraud rings more effectively and banned 333K bad accounts from Play for violations like confirmed malware and repeated severe policy violations.
Additionally, almost 200K app submissions were rejected or remediated to ensure proper use of sensitive permissions such as background location or SMS access. To help safeguard user privacy at scale, we partnered with SDK providers to limit sensitive data access and sharing, enhancing the privacy posture for over 31 SDKs impacting 790K+ apps. We also significantly expanded the Google Play SDK Index, which now covers the SDKs used in almost 6 million apps across the Android ecosystem. This valuable resource helps developers make better SDK choices, boosts app quality and minimizes integration risks.
Building on our success with the App Defense Alliance (ADA), we partnered with Microsoft and Meta as steering committee members in the newly restructured ADA under the Joint Development Foundation, part of the Linux Foundation family. The Alliance will support industry-wide adoption of app security best practices and guidelines, as well as countermeasures against emerging security risks.
Additionally, we announced new Play Store transparency labeling to highlight VPN apps that have completed an independent security review through App Defense Alliance’s Mobile App Security Assessment (MASA). When a user searches for VPN apps, they will now see a banner at the top of Google Play that educates them about the “Independent security review” badge in the Data safety section. This helps users see at-a-glance that a developer has prioritized security and privacy best practices and is committed to user safety.
To better protect our customers who install apps outside of the Play Store, we made Google Play Protect’s security capabilities even more powerful with real-time scanning at the code-level to combat novel malicious apps. Our security protections and machine learning algorithms learn from each app submitted to Google for review and we look at thousands of signals and compare app behavior. This new capability has already detected over 5 million new, malicious off-Play apps, which helps protect Android users worldwide.
Last year we updated Play policies around Generative AI apps, disruptive notifications, and expanded privacy protections. We also are raising the bar for new personal developer accounts by requiring new testing requirements before developers can make their app available on Google Play. By testing their apps, getting feedback and ensuring everything is ready before they launch, developers are able to bring more high quality content to Play users. In order to increase trust and transparency, we’ve introduced expanded developer verification requirements, including D-U-N-S numbers for organizations and a new “About the developer” section.
To give users more control over their personal data, apps that enable account creation now need to provide an option to initiate account and data deletion from within the app and online. This web requirement is especially important so that a user can request account and data deletion without having to reinstall an app. To simplify the user experience, we have also incorporated this as a feature within the Data safety section of the Play Store.
With each iteration of the Android operating system (including its robust set of APIs), a myriad of enhancements are introduced, aiming to elevate the user experience, bolster security protocols, and optimize the overall performance of the Android platform. To further safeguard our customers, approximately 1.5 million applications that do not target the most recent APIs are no longer available in the Play Store to new users who have updated their devices to the latest Android version.
Protecting users and developers on Google Play is paramount and ever-evolving. We're launching new security initiatives in 2024, including removing apps from Play that are not transparent about their privacy practices.
We also recently filed a lawsuit in federal court against two fraudsters who made multiple misrepresentations to upload fraudulent investment and crypto exchange apps on Play to scam users. This lawsuit is a critical step in holding these bad actors accountable and sending a clear message that we will aggressively pursue those who seek to take advantage of our users.
We're constantly working on new ways to protect your experience on Google Play and across the entire Android ecosystem, and we look forward to sharing more.
In accordance with the EU's Digital Services Act (DSA) reporting requirements, Google Play now calculates policy violations based on developer communications sent. ↩
As security professionals, we're constantly looking for ways to reduce risk and improve our workflow's efficiency. We've made great strides in using AI to identify malicious content, block threats, and discover and fix vulnerabilities. We also published the Secure AI Framework (SAIF), a conceptual framework for secure AI systems to ensure we are deploying AI in a responsible manner.
Today we are highlighting another way we use generative AI to help the defenders gain the advantage: Leveraging LLMs (Large Language Model) to speed-up our security and privacy incidents workflows.
Incident management is a team sport. We have to summarize security and privacy incidents for different audiences including executives, leads, and partner teams. This can be a tedious and time-consuming process that heavily depends on the target group and the complexity of the incident. We estimate that writing a thorough summary can take nearly an hour and more complex communications can take multiple hours. But we hypothesized that we could use generative AI to digest information much faster, freeing up our incident responders to focus on other more critical tasks - and it proved true. Using generative AI we could write summaries 51% faster while also improving the quality of them.
When suspecting a potential data incident, for example,we follow a rigorous process to manage it. From the identification of the problem, the coordination of experts and tools, to its resolution and then closure. At Google, when an incident is reported, our Detection & Response teams work to restore normal service as quickly as possible, while meeting both regulatory and contractual compliance requirements. They do this by following the five main steps in the Google incident response program:
Identification: Monitoring security events to detect and report on potential data incidents using advanced detection tools, signals, and alert mechanisms to provide early indication of potential incidents.
Coordination: Triaging the reports by gathering facts and assessing the severity of the incident based on factors such as potential harm to customers, nature of the incident, type of data that might be affected, and the impact of the incident on customers. A communication plan with appropriate leads is then determined.
Resolution: Gathering key facts about the incident such as root cause and impact, and integrating additional resources as needed to implement necessary fixes as part of remediation.
Closure: After the remediation efforts conclude, and after a data incident is resolved, reviewing the incident and response to identify key areas for improvement.
Continuous improvement: Is crucial for the development and maintenance of incident response programs. Teams work to improve the program based on lessons learned, ensuring that necessary teams, training, processes, resources, and tools are maintained.
Google’s Incident Response Process diagram flow
Our detection and response processes are critical in protecting our billions of global users from the growing threat landscape, which is why we’re continuously looking for ways to improve them with the latest technologies and techniques. The growth of generative AI has brought with it incredible potential in this area, and we were eager to explore how it could help us improve parts of the incident response process. We started by leveraging LLMs to not only pioneer modern approaches to incident response, but also to ensure that our processes are efficient and effective at scale.
Managing incidents can be a complex process and an additional factor is effective internal communication to leads, executives and stakeholders on the threats and status of incidents. Effective communication is critical as it properly informs executives so that they can take any necessary actions, as well as to meet regulatory requirements. Leveraging LLMs for this type of communication can save significant time for the incident commanders while improving quality at the same time.
Given that LLMs have summarization capabilities, we wanted to explore if they are able to generate summaries on par, or as well as humans can. We ran an experiment that took 50 human-written summaries from native and non-native English speakers, and 50 LLM-written ones with our finest (and final) prompt, and presented them to security teams without revealing the author.
We learned that the LLM-written summaries covered all of the key points, they were rated 10% higher than their human-written equivalents, and cut the time necessary to draft a summary in half.
Comparison of human vs LLM content completeness
Comparison of human vs LLM writing styles
Leveraging generative AI is not without risks. In order to mitigate the risks around potential hallucinations and errors, any LLM generated draft must be reviewed by a human. But not all risks are from the LLM - human misinterpretation of a fact or statement generated by the LLM can also happen. That is why it’s important to ensure there is human accountability, as well as to monitor quality and feedback over time.
Given that our incidents can contain a mixture of confidential, sensitive, and privileged data, we had to ensure we built an infrastructure that does not store any data. Every component of this pipeline - from the user interface to the LLM to output processing - has logging turned off. And, the LLM itself does not use any input or output for re-training. Instead, we use metrics and indicators to ensure it is working properly.
The type of data we process during incidents can be messy and often unstructured: Free-form text, logs, images, links, impact stats, timelines, and code snippets. We needed to structure all of that data so the LLM “knew” which part of the information serves what purpose. For that, we first replaced long and noisy sections of codes/logs by self-closing tags (<Code Section/> and <Logs/>) both to keep the structure while saving tokens for more important facts and to reduce risk of hallucinations.
During prompt engineering, we refined this approach and added additional tags such as <Title>, <Actions Taken>, <Impact>, <Mitigation History>, <Comment> so the input’s structure becomes closely mirrored to our incident communication templates. The use of self-explanatory tags allowed us to convey implicit information to the model and provide us with aliases in the prompt for the guidelines or tasks, for example by stating “Summarize the <Security Incident>”.
Sample {incident} input
Once we added structure to the input, it was time to engineer the prompt. We started simple by exploring how LLMs can view and summarize all of the current incident facts with a short task:
Caption: First prompt version
Limits of this prompt:
The summary was too long, especially for executives trying to understand the risk and impact of the incident
Some important facts were not covered, such as the incident’s impact and its mitigation
The writing was inconsistent and not following our best practices such as “passive voice”, “tense”, “terminology” or “format”
Some irrelevant incident data was being integrated into the summary from email threads
The model struggled to understand what the most relevant and up-to-date information was
For version 2, we tried a more elaborate prompt that would address the problems above: We told the model to be concise and we explained what a well-written summary should be: About the main incident response steps (coordination and resolution).
Second prompt version
The summaries still did not always succinctly and accurately address the incident in the format we were expecting
At times, the model lost sight of the task or did not take all the guidelines into account
The model still struggled to stick to the latest updates
We noticed a tendency to draw conclusions on hypotheses with some minor hallucinations
For the final prompt, we inserted 2 human-crafted summary examples and introduced a <Good Summary> tag to highlight high quality summaries but also to tell the model to immediately start with the summary without first repeating the task at hand (as LLMs usually do).
Final prompt
This produced outstanding summaries, in the structure we wanted, with all key points covered, and almost without any hallucinations.
In integrating the prompt into our workflow, we wanted to ensure it was complementing the work of our teams, vs. solely writing communications. We designed the tooling in a way that the UI had a ‘Generate Summary’ button, which would pre-populate a text field with the summary that the LLM proposed. A human user can then either accept the summary and have it added to the incident, do manual changes to the summary and accept it, or discard the draft and start again.
UI showing the ‘generate draft’ button and LLM proposed summary around a fake incident
Our newly-built tool produced well-written and accurate summaries, resulting in 51% time saved, per incident summary drafted by an LLM, versus a human.
Time savings using LLM-generated summaries (sample size: 300)
The only edge cases we have seen were around hallucinations when the input size was small in relation to the prompt size. In these cases, the LLM made up most of the summary and key points were incorrect. We fixed this programmatically: If the input size is smaller than 200 tokens, we won’t call the LLM for a summary and let the humans write it.
Given these results, we explored other ways to apply and build upon the summarization success and apply it to more complex communications. We improved upon the initial summary prompt and ran an experiment to draft executive communications on behalf of the Incident Commander (IC). The goal of this experiment was to ensure executives and stakeholders quickly understand the incident facts, as well as allow ICs to relay important information around incidents. These communications are complex because they go beyond just a summary - they include different sections (such as summary, root cause, impact, and mitigation), follow a specific structure and format, as well as adhere to writing best practices (such as neutral tone, active voice instead of passive voice, minimize acronyms).
This experiment showed that generative AI can evolve beyond high level summarization and help draft complex communications. Moreover, LLM-generated drafts, reduced time ICs spent writing executive summaries by 53% of time, while delivering at least on-par content quality in terms of factual accuracy and adherence to writing best practices.
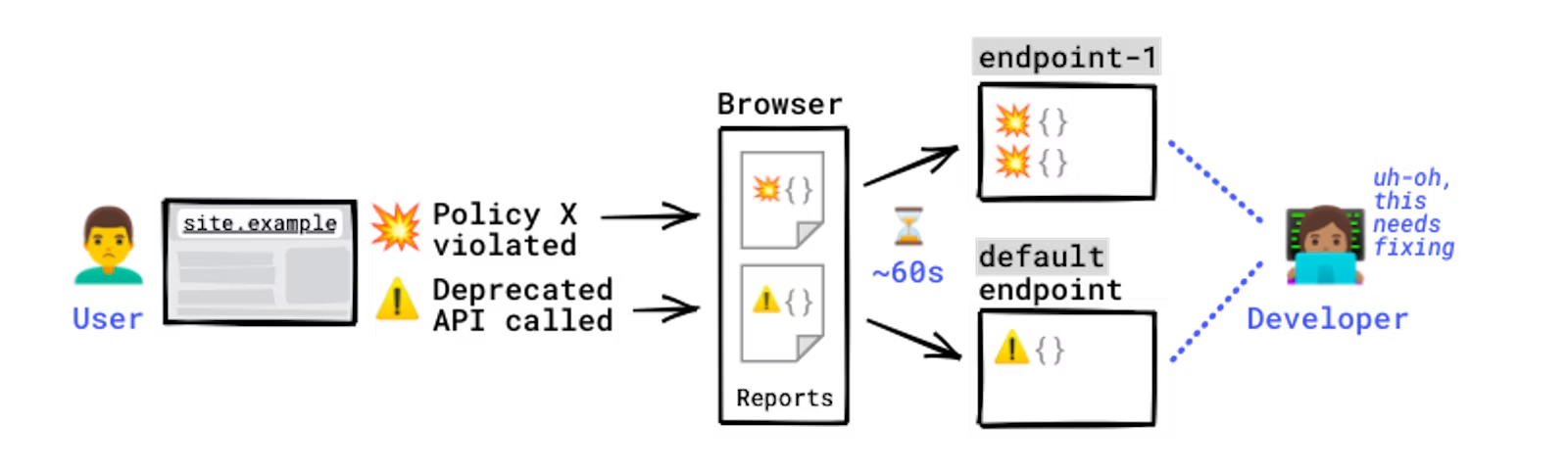
The Reporting API is an emerging web standard that provides a generic reporting mechanism for issues occurring on the browsers visiting your production website. The reports you receive detail issues such as security violations or soon-to-be-deprecated APIs, from users’ browsers from all over the world.
Collecting reports is often as simple as specifying an endpoint URL in the HTTP header; the browser will automatically start forwarding reports covering the issues you are interested in to those endpoints. However, processing and analyzing these reports is not that simple. For example, you may receive a massive number of reports on your endpoint, and it is possible that not all of them will be helpful in identifying the underlying problem. In such circumstances, distilling and fixing issues can be quite a challenge.
In this blog post, we'll share how the Google security team uses the Reporting API to detect potential issues and identify the actual problems causing them. We'll also introduce an open source solution, so you can easily replicate Google's approach to processing reports and acting on them.
Some errors only occur in production, on users’ browsers to which you have no access. You won't see these errors locally or during development because there could be unexpected conditions real users, real networks, and real devices are in. With the Reporting API, you directly leverage the browser to monitor these errors: the browser catches these errors for you, generates an error report, and sends this report to an endpoint you've specified.
How reports are generated and sent.
Errors you can monitor with the Reporting API include:
For a full list of error types you can monitor, see use cases and report types.
The Reporting API is activated and configured using HTTP response headers: you need to declare the endpoint(s) you want the browser to send reports to, and which error types you want to monitor. The browser then sends reports to your endpoint in POST requests whose payload is a list of reports.
Example setup:
# Example setup to receive CSP violations reports, Document-Policy violations reports, and Deprecation reports
Reporting-Endpoints: main-endpoint="https://reports.example/main", default="https://reports.example/default"
# CSP violations and Document-Policy violations will be sent to `main-endpoint`
Content-Security-Policy: script-src 'self'; object-src 'none'; report-to main-endpoint;
Document-Policy: document-write=?0; report-to=main-endpoint;
# Deprecation reports are generated automatically and don't need an explicit endpoint; they're always sent to the `default` endpoint
Note: Some policies support "report-only" mode. This means the policy sends a report, but doesn't actually enforce the restriction. This can help you gauge if the policy is working effectively.
Chrome users whose browsers generate reports can see them in DevTools in the Application panel:
Example of viewing reports in the Application panel of DevTools.
You can generate various violations and see how they are received on a server in the reporting endpoint demo:
Example violation reports
The Reporting API is supported by Chrome, and partially by Safari as of March 2024. For details, see the browser support table.
Google benefits from being able to uplift security at scale. Web platform mitigations like Content Security Policy, Trusted Types, Fetch Metadata, and the Cross-Origin Opener Policy help us engineer away entire classes of vulnerabilities across hundreds of Google products and thousands of individual services, as described in this blogpost.
One of the engineering challenges of deploying security policies at scale is identifying code locations that are incompatible with new restrictions and that would break if those restrictions were enforced. There is a common 4-step process to solve this problem:
With the Reporting API, we have the ability to run this cycle using a unified reporting endpoint and a single schema for several security features. This allows us to gather reports for a variety of features across different browsers, code paths, and types of users in a centralized way.
Note: A violation report is generated when an entity is attempting an action that one of your policies forbids. For example, you've set CSP on one of your pages, but the page is trying to load a script that's not allowed by your CSP. Most reports generated via the Reporting API are violation reports, but not all — other types include deprecation reports and crash reports. For details, see Use cases and report types.
Unfortunately, it is common for noise to creep into streams of violation reports, which can make finding incompatible code locations difficult. For example, many browser extensions, malware, antivirus software, and devtools users inject third-party code into the DOM or use forbidden APIs. If the injected code is incompatible with the policy, this can lead to violation reports that cannot be linked to our code base and are therefore not actionable. This makes triaging reports difficult and makes it hard to be confident that all code locations have been addressed before enforcing new policies.
Over the years, Google has developed a number of techniques to collect, digest, and summarize violation reports into root causes. Here is a summary of the most useful techniques we believe developers can use to filter out noise in reported violations:
It is often the case that a piece of code that is incompatible with the policy executes several times throughout the lifetime of a browser tab. Each time this happens, a new violation report is created and queued to be sent to the reporting endpoint. This can quickly lead to a large volume of individual reports, many of which contain redundant information. Because of this, grouping violation reports into clusters enables developers to abstract away individual violations and think in terms of root causes. Root causes are simpler to understand and can speed up the process of identifying useful refactorings.
Let's take a look at an example to understand how violations may be grouped. For instance, a report-only CSP that forbids the use of inline JavaScript event handlers is deployed. Violation reports are created on every instance of those handlers and have the following fields set:
blockedURL
inline
scriptSample
documentURL
Most of the time, these three fields uniquely identify the inline handlers in a given URL, even if the values of other fields differ. This is common when there are tokens, timestamps, or other random values across page loads. Depending on your application or framework, the values of these fields can differ in subtle ways, so being able to do fuzzy matches on reporting values can go a long way in grouping violations into actionable clusters. In some cases, we can group violations whose URL fields have known prefixes, for example all violations with URLs that start with chrome-extension, moz-extension, or safari-extension can be grouped together to set root causes in browser extensions aside from those in our codebase with a high degree of confidence.
chrome-extension
moz-extension
safari-extension
Developing your own grouping strategies helps you stay focused on root causes and can significantly reduce the number of violation reports you need to triage. In general, it should always be possible to select fields that uniquely identify interesting types of violations and use those fields to prioritize the most important root causes.
Another way of distinguishing non-actionable from actionable violation reports is ambient information. This is data that is contained in requests to our reporting endpoint, but that is not included in the violation reports themselves. Ambient information can hint at sources of noise in a client's set up that can help with triage:
Some types of violations have a source_file field or equivalent. This field represents the JavaScript file that triggered the violation and is usually accompanied by a line and column number. These three bits of data are a high-quality signal that can point directly to lines of code that need to be refactored.
source_file
Nevertheless, it is often the case that source files fetched by browsers are compiled or minimized and don't map directly to your code base. In this case, we recommend you use JavaScript source maps to map line and column numbers between deployed and authored files. This allows you to translate directly from violation reports to lines of source code, yielding highly actionable report groups and root causes.
The Reporting API sends browser-side events, such as security violations, deprecated API calls, and browser interventions, to the specified endpoint on a per-event basis. However, as explained in the previous section, to distill the real issues out of those reports, you need a data processing system on your end.
Fortunately, there are plenty of options in the industry to set up the required architecture, including open source products. The fundamental pieces of the required system are the following:
Solutions for each of the components listed above are made available by public cloud platforms, SaaS services, and as open source software. See the Alternative solutions section for details, and the following section outlining a sample application.
To help you understand how to receive reports from browsers and how to handle these received reports, we created a small sample application that demonstrates the following processes that are required for distilling web application security issues from reports sent by browsers:
Although this sample is relying on Google Cloud, you can replace each of the components with your preferred technologies. An overview of the sample application is illustrated in the following diagram:
Components described as green boxes are components that you need to implement by yourself. Forwarder is a simple web server that receives reports in the JSON format and converts them to the schema for Bigtable. Beam-collector is a simple Apache Beam pipeline that filters noisy reports, aggregates relevant reports into the shape of constellations, and saves them as CSV files. These two components are the key parts to make better use of reports from the Reporting API.
Because this is a runnable sample application, you are able to deploy all components to a Google Cloud project and see how it works by yourself. The detailed prerequisites and the instructions to set up the sample system are documented in the README.md file.
Aside from the open source solution we shared, there are a number of tools available to assist in your usage of the Reporting API. Some of them include:
Besides pricing, consider the following points when selecting alternatives:
In this article, we explained how web developers can collect client-side issues by using the Reporting API, and the challenges of distilling the real problems out of the collected reports. We also introduced how Google solves those challenges by filtering and processing reports, and shared an open source project that you can use to replicate a similar solution. We hope this information will motivate more developers to take advantage of the Reporting API and, in consequence, make their website more secure and sustainable.









.png)





