Memory safety bugs are the most numerous category of Chrome security issues and we’re continuing to investigate many solutions – both in C++ and in new programming languages. The most common type of memory safety bug is the “use-after-free”. We recently posted about an exciting series of technologies designed to prevent these. Those technologies (collectively, *Scan, pronounced “star scan”) are very powerful but likely require hardware support for sufficient performance.
Today we’re going to talk about a different approach to solving the same type of bugs.
It’s hard, if not impossible, to avoid use-after-frees in a non-trivial codebase. It’s rarely a mistake by a single programmer. Instead, one programmer makes reasonable assumptions about how a bit of code will work, then a later change invalidates those assumptions. Suddenly, the data isn’t valid as long as the original programmer expected, and an exploitable bug results.
These bugs have real consequences. For example, according to Google Threat Analysis Group, a use-after-free in the ChromeHTML engine was exploited this year by North Korea.
Half of the known exploitable bugs in Chrome are use-after-frees:
Diving Deeper: Not All Use-After-Free Bugs Are Equal
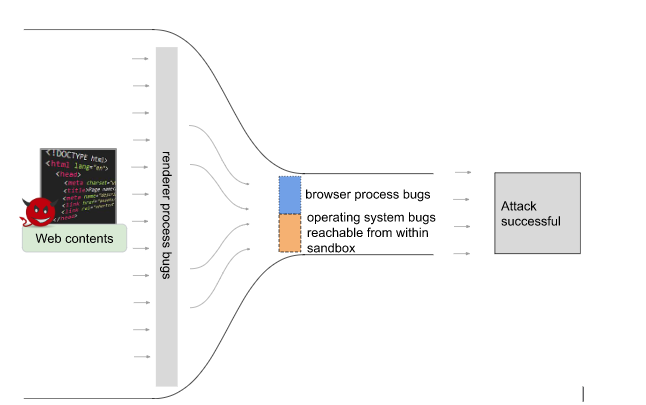
Chrome has a multi-process architecture, partly to ensure that web content is isolated into a sandboxed “renderer” process where little harm can occur. An attacker therefore usually needs to find and exploit two vulnerabilities - one to achieve code execution in the renderer process, and another bug to break out of the sandbox.
The first stage is often the easier one. The attacker has lots of influence in the renderer process. It’s easy to arrange memory in a specific way, and the renderer process acts upon many different kinds of web content, giving a large “attack surface” that could potentially be exploited.
The second stage, escaping the renderer sandbox, is trickier. Attackers have two options how to do this:
We imagine the attackers squeezing through the narrow part of a funnel:
Here’s a sample of 100 recent high severity Chrome security bugs that made it to the stable channel, divided by root cause and by the process they affect.
You might notice:
As you can see, the biggest category of bugs in each process is: V8 in the renderer process (JavaScript engine logic bugs - work in progress) and use-after-free bugs in the browser process. If we can make that “thin” bit thinner still by removing some of those use-after-free bugs, we make the whole job of Chrome exploitation markedly harder.
MiraclePtr: Preventing Exploitation of Use-After-Free Bugs
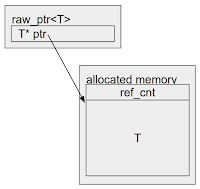
This is where MiraclePtr comes in. It is a technology to prevent exploitation of use-after-free bugs. Unlike aforementioned *Scan technologies that offer a non-invasive approach to this problem, MiraclePtr relies on rewriting the codebase to use a new smart pointer type, raw_ptr<T>. There are multiple ways to implement MiraclePtr. We came up with ~10 algorithms and compared the pros and cons. After analyzing their performance overhead, memory overhead, security protection guarantees, developer ergonomics, etc., we concluded that BackupRefPtr was the most promising solution.
class A { ... }; class B { B(A* a) : a_(a) {} void doSomething() { a_->doSomething(); } raw_ptr<A> a_; // MiraclePtr }; std::unique_ptr<A> a = std::make_unique<A>(); std::unique_ptr<B> b = std::make_unique<B>(a.get()); […] a = nullptr; // The free is delayed because the MiraclePtr is still pointing to the object. b->doSomething(); // Use-after-free is neutralized.
We successfully rewrote more than 15,000 raw pointers in the Chrome codebase into raw_ptr<T>, then enabled BackupRefPtr for the browser process on Windows and Android (both 64 bit and 32 bit) in Chrome 102 Stable. We anticipate that MiraclePtr meaningfully reduces the browser process attack surface of Chrome by protecting ~50% of use-after-free issues against exploitation. We are now working on enabling BackupRefPtr in the network, utility and GPU processes, and for other platforms. In the end state, our goal is to enable BackupRefPtr on all platforms because that ensures that a given pointer is protected for all users of Chrome.
Balancing Security and Performance
There is no free lunch, however. This security protection comes at a cost, which we have carefully weighed in our decision making.
Unsurprisingly, the main cost is memory. Luckily, related investments into PartitionAlloc over the past year led to 10-25% total memory savings, depending on usage patterns and platforms. So we were able to spend some of those savings on security: MiraclePtr increased the memory usage of the browser process 4.5-6.5% on Windows and 3.5-5% on Android1, still well below their previous levels. While we were worried about quarantined memory, in practice this is a tiny fraction (0.01%) of the browser process usage. By far the bigger culprit is the additional memory needed to store the reference count. One might think that adding 4 bytes to each allocation wouldn’t be a big deal. However, there are many small allocations in Chrome, so even the 4B overhead is not negligible. PartitionAlloc also uses pre-defined bucket sizes, so this extra 4B pushes certain allocations (particularly power-of-2 sized) into a larger bucket, e.g. 4096B->5120B.
We also considered the performance cost. Adding an atomic increment/decrement on common operations such as pointer assignment has unavoidable overhead. Having excluded a number of performance-critical pointers, we drove this overhead down until we could gain back the same margin through other performance optimizations. On Windows, no statistically significant performance regressions were observed on most of our top-level performance metrics like Largest Contentful Paint, First Input Delay, etc. The only adverse change there1 is an increase of the main thread contention (~7%). On Android1, in addition to a similar increase in the main thread contention (~6%), there were small regressions in First Input Delay (~1%), Input Delay (~3%) and First Contentful Paint (~0.5%). We don't anticipate these regressions to have a noticeable impact on user experience, and are confident that they are strongly outweighed by the additional safety for our users.
We should emphasize that MiraclePtr currently protects only class/struct pointer fields, to minimize the overhead. As future work, we are exploring options to expand the pointer coverage to on-stack pointers so that we can protect against more use-after-free bugs.
Note that the primary goal of MiraclePtr is to prevent exploitation of use-after-free bugs. Although it wasn’t designed for diagnosability, it already helped us find and fix a number of bugs that were previously undetected. We have ongoing efforts to make MiraclePtr crash reports even more informative and actionable.
Continue to Provide Us Feedback
Last but not least, we’d like to encourage security researchers to continue to report issues through the Chrome Vulnerability Reward Program, even if those issues are mitigated by MiraclePtr. We still need to make MiraclePtr available to all users, collect more data on its impact through reported issues, and further refine our processes and tooling. Until that is done, we will not consider MiraclePtr when determining the severity of a bug or the reward amount.
1 Measured in Chrome 99.
Postar um comentário





Nenhum comentário :
Postar um comentário